Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
10.1 Quellen für UML/P-Refactoring-Regeln
10.2 Additive Methode für Datenstrukturwechsel
10.3 Zusammenfassung der Refactoring-Techniken
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
10.1 Quellen für UML/P-Refactoring-Regeln
Nach der allgemeinen und durch theoretische Überlegungen fundierten Betrachtung von Modelltransformationen im letzten Abschnitt, werden diese Überlegungen nun an konkreten Beispielen umgesetzt. Dabei werden vor allem Mechanismen und Quellen diskutiert, Refactoring-Regeln aus bekannten Ansätzen auf die UML/P zu transferieren.
Refactoring-Schritte auf der UML/P tangieren meistens mehrere Notationen. So ist bei der Verschiebung einer Methode im Klassendiagramm auch oft ein Teil des Java/P-Codes, der Sequenzdiagramme und sogar Statecharts betroffen. Eine Diskussion von Refactoring-Techniken für UML/P kann daher nicht vollständig isoliert für einzelne Notationen erfolgen.
Die Granularität eines Refactorings ist so zu wählen, dass die Transformationsschritte beherrschbar bleiben und die automatisierten Tests regelmäßig ausgeführt werden können. Zu große oder zu wenig durch Tests unterstützte Schritte führen zum Big-Bang-Syndrom mit viel Aufwand für die Fehlersuche. Das bedeutet, dass große Refactorings soweit wie notwendig in kleine Schritte zerlegt und ein Plan zur Umsetzung erstellt werden sollte. Dennoch gibt es viele notwendigerweise größere Refactorings, die ganz bestimmte, teilweise spezialisierte Problemstellungen behandeln.
Die UML/P ist im Vergleich zu Java-Programmen relativ kompakt, indem sie eine Trennung zwischen technischem und applikationsspezifischem Code erlaubt, Hilfsmethoden automatisch generiert und durch die Trennung verschiedener Sichten einen besseren Überblick ermöglicht. Diese Kompaktheit der UML/P erlaubt die Beherrschung noch größerer Refactoring-Schritte als dies mit Java der Fall ist. So unterstützt ein Klassendiagramm die Planung des Refactorings und die Verwendung von OCL-Invarianten erlaubt die Modellierung und Prüfung von Annahmen, die für ein Refactoring getroffen werden. Diese Überlegung führt zu der in Abschnitt 10.2 diskutierten Vorgehensweise für die Durchführung von größeren Datenstrukturwechseln mithilfe von Refactoring bei denen mehrere UML/P-Notationen eine wesentliche Rolle spielen.
Während für objektorientierte Programmiersprachen wie Java oder Smalltalk unter anderem mit [Fow99] bereits Sammlungen kleiner und mittlerer Refactorings vorliegen, werden für Modellierungssprachen wie die UML/P solche Refactoring-Schritte erst aufgebaut. [Dob10] gibt eine aktuelle Übersicht über Techniken und Ansätze zur von UML Modellen, der sich vor allem auf Klassendiagramme und ausführbare Varianten der UML konzentriert.
Am weitesten sind noch Transformationen auf Klassendiagramme elaboriert [SPTJ01, Ast02, GSMD03]. In [Ast02] wird zum Beispiel ein Ansatz beschrieben, der UML-Klassendiagramme als Unterstützung für das Refactoring von Java-Programmen nutzt. Dabei werden aus dem existierenden Code Klassendiagramme extrahiert, um damit Codedefizite zu identifizieren.
Graphgrammatiken [Nag79] und darauf basierende Werkzeuge bieten eine exzellente Basis für Transformationsansätze. Frühe solche Ansätze für die graphische Modellierungssprache UML sind in [EH00b, EHHS00] beschrieben. In [EHHS00] werden diese Transformationen sogar zur Beschreibung von dynamischen Systemabläufen über die Refaktorisierung der Systemstruktur hinaus eingesetzt.
UML-Diagramme werden in der aktuellen Literatur noch wenig als Primärziel für Refactorings verstanden. Dabei ist die Anwendung insbesondere auf die konstruktiven Beschreibungstechniken, wie Klassendiagramme, Statecharts und die OCL, interessant. Die Anpassung exemplarischer Beschreibungen, wie Objekt- und Sequenzdiagramme ist demgegenüber vergleichsweise einfach. Da letztere vor allem zur Definition von Tests herangezogen werden, ist deren Anpassung immer dann notwendig, wenn ein Test nach einem Refactoring scheitert. Dabei kann es durchaus sinnvoll sein, aus einem gescheiterten Test mehrere neue zu entwickeln, wenn zum Beispiel ein einzelner Methodenaufruf durch ein Protokoll mit einer Serie von zusammenhängenden Methodenaufrufen ersetzt wurde und verschiedene Reihenfolgen und Abbruchsmöglichkeiten im Protokoll getestet werden sollen.
Die das beobachtbare Verhalten erhaltenden Transformationen von Statecharts wurden bereits in Abschnitt 5.6.2, Band 1 ausführlich diskutiert. Dabei wurde eine Sammlung von zielorientierten Regeln vorgestellt, die es erlauben, Statecharts zu vereinfachen, indem zum Beispiel hierarchische Zustände flach gedrückt werden. Viele dieser Regeln können auch in umgekehrter Richtung angewandt werden. Manche Regeln jedoch, wie zum Beispiel die Reduktion von Nichtdeterminismus im Statechart sind eine echte Verfeinerung in dem in Abschnitt 9.3.2 definierten Sinn. Aus den in Abschnitt 9.2 beschriebenen ökonomischen Gesichtspunkten, wird aus der heutigen Sicht ein Refactoring von Statecharts vor allem für Systeme oder Systemteile mit komplexen Zustandsräumen und hoher Kritikalität als sinnvoll erachtet. Dazu gehören beispielsweise Avioniksysteme, Sicherheitsprotokolle oder komplexe Transaktionslogiken in Banksystemen.
Ziel dieses Abschnitts ist es, zu diskutieren, wie Regelsätze für die Modellierungssprache UML/P aus anderen Refactoring-Ansätzen übernommen werden können und welche Refactorings es bereits gibt. Dabei soll kein vollständiger Katalog entwickelt werden. Stattdessen wird anhand ausgesuchter Beispiele demonstriert, wie Refactoring-Regeln für die UML/P definiert werden und welche Effekte damit erzielt werden können. Damit wird also nicht ein Katalog an Refactorings, sondern eine Technik zur eigenständigen Entwicklung von Refactoring-Regeln zur Verfügung gestellt. Dazu gehört insbesondere auch die im nächsten Abschnitt diskutierte Vorgehensweise zum Refactoring von Datenstrukturen, die auch dazu genutzt werden kann, neue Refactoring-Regeln aus konkreten Anwendungen heraus zu extrahieren.
10.1.1 Definition und Darstellung von Refactoring-Regeln
Ein Refactoring kann ähnlich wie eine Transformation für die Codegenerierung in zwei Formen beschrieben werden. Eine technische, detaillierte und präzise Beschreibung eignet sich vor allem für die Umsetzung in Werkzeugen. Sie benötigt als Grundlage die abstrakte Syntax sowie Kontextbedingungen, die präzise auf dieser abstrakten Syntax definiert sind.
Eine zweite Form der Darstellung ist für den Anwender geeignet. Das Prinzip wird motiviert und anhand eines relativ allgemeinen, aber oft nicht alle Fälle abdeckenden Beispiels erklärt. Kontextbedingungen werden eher informell, aber doch präzise diskutiert und Sonderfälle erläutert. Wie bei Mustern üblich, werden konkrete Beispiele angegeben. Eine Diskussion der Konsequenzen, Vor- und Nachteile ist insbesondere bei größeren Refactorings sinnvoll. Als letztes werden Verweise auf verwandte Refactorings sowie auf die Umkehrung des Refactorings angegeben.
Das Format zur Darstellung eines Refactorings lehnt sich also an das Format für Codegenerierung aus Tabelle 4.11 an und ist in Tabelle 10.1 als Schablone dargestellt.
In [Fow99] werden Refactoring-Regeln durchgängig als Tripel Motivation, Mechanik und Beispiel dargestellt. Der Abschnitt Mechanik beschreibt dabei genau wie hier eine operative Liste von Einzelschritten, die zur Durchführung des Refactorings sinnvoll sind. Dabei werden Sonderfälle ebenfalls behandelt.
|
|
|
|||||
|
Schablone für die Darstellung von Refactoring-Regeln
|
||||||
|
|
|
|||||
|
Problem |
Welches Problem besteht und soll durch diese Regel behoben werden? |
|||||
|
|
||||||
|
Ziel |
Soweit nicht durch Motivation und Problembeschreibung bereits klar, werden hier die Ziele des Refactorings noch einmal beschrieben. |
|||||
|
|
||||||
|
Motivation |
Warum und wann wird die Refactoring-Regel eingesetzt? Welche Verbesserungen ergeben sich dadurch für die Softwareentwicklung? |
|||||
|
|
||||||
|
Refactoring |
Meist gibt es eine primäre Transformationsregel für das Refactoring, die in folgender Form dargestellt wird:
|
|||||
|
|
|
|||||
|
|
||||||
|
Weitere Refactorings |
Begleitend zur primären Transformation ergeben sich meist zusätzlich notwendige Transformationen, die in analoger Form dargestellt werden. |
|||||
|
|
||||||
|
Implementierung |
Technische Details wie zum Beispiel die Modifikation von Methodenrümpfen werden hier dargestellt und diskutiert. |
|||||
|
|
||||||
|
Beispiele |
Beispiele können zur Erläuterung des Prinzips und zur Diskussion von Sonderfällen genutzt werden. |
|||||
|
|
||||||
|
|
||||||
|
Beachtenswert |
Dieser Abschnitt rundet durch zusätzliche Betrachtungen, Hinweise und der Diskussion potentieller Problemstellungen die Beschreibung ab. Insbesondere wird darauf hingewiesen, welche Konsequenzen, Vor- und Nachteile das beschriebene Refactoring hat. |
|||||
|
|
|
|||||
|
Tabelle 10.1.: Schablone für die Darstellung von Refactoring-Regeln
|
||||||
Nachdem die Motivation und die Hintergründe für Refactoring und das Aussehen von Refactoring-Regeln geklärt wurden, wird in Abbildung 10.2 eine für dieses Buch gültige Begriffsbestimmung auf Basis der Abbildung 9.1 vorgenommen.
- Refactoring
- ist eine Technik zur regelbasierten Transformation von Modellen unter Erhalt des extern beobachtbaren Verhaltens. Ein Refactoring kann in eine Serie von einzelnen Schritten aufgeteilt sein.
- Refactoring-Regel
- ist eine zielgerichtete Vorschrift zur Durchführung eines Refactorings. Sie beinhaltet eine Serie von mit Schemavariablen formulierten, beobachtungsinvarianten Modelltransformationen, die auf das Ausgangsmodell anzuwenden sind, eine Motivation für deren Anwendung und eine Diskussion der Auswirkungen.
- Refactoring-Schritt
- ist die Anwendung einer Refactoring-Regel an einer konkreten Stelle.
- Beobachtung
- ist ein Test, bestehend aus mehreren Modellen, die vom System geforderte Eigenschaften beschreiben.
- Externe Beobachtung
- ist eine Beobachtung, die nicht verändert werden darf, ohne projektexterne Konsultationen zu erfordern. Externe Beobachtungen werden durch Akzeptanztests und Tests über Schnittstellen zu Nachbarsystemen, fixierte Frameworks, etc. festgelegt.
10.1.2 Refactoring in Java/P
Die in der UML eingebettete und in Anhang B, Band 1 definierte Programmiersprache Java/P unterscheidet sich in ihrer Syntax kaum von der Java-Standardversion. Wesentlichster Unterschied ist, dass gemäß der in Kapitel 4 und Kapitel 5 beschriebenen Codegenerierung die damit beschriebenen Coderümpfe einer Umsetzung unterliegen. Dabei werden beispielsweise Attributzugriffe in get- und set-Methoden umgewandelt. Attribute sind damit immer gekapselt und einige der in [Fow99] definierten Refactorings für Java/P unnötig. So wird zum Beispiel die Refactoring-Regel „Encapsulate Field“ [Fow99, S. 206] durch einen Codegenerator automatisch durchgeführt. Dies hat den Vorteil, dass die Kapselung zwar sichergestellt ist, dem Entwickler aber in der Modellierung die Kapselungsmethoden verborgen bleiben.
Andere Refactoring-Regeln aus [Opd92] und [Fow99] lassen sich übernehmen. In [Opd92] sind 26 Low-Level-Refactorings für C++ angegeben. Davon sind jeweils drei zur Erzeugung und Löschung von Programmelementen (Klassen, Funktionen, Attributen), 15 für die Anpassung vorhandener Programmelemente und zwei für die Verschiebung vorgesehen. Drei Refactorings sind Kompositionen vorheriger Transformationen. Drei zusätzliche Refactorings dienen der Generalisierung und Spezialisierung der Klassenhierarchie und der Behandlung von Aggregation und wirken damit über einzelne Klassen hinaus. [Fow99] enthält entsprechende Analogien für Java. Deshalb wird nachfolgend die Übertragbarkeit der einzelnen Refactoring-Regeln aus [Fow99] auf Java/P beziehungsweise Diagramme der UML/P diskutiert.
Refactorings in [Fow99]
In [Fow99] sind 72 Refactoring-Regeln enthalten, die dort als initialer und unvollständiger Refactoring-Katalog (S. 103) bezeichnet werden, der weiter ausgebaut werden kann. Dies fand unter anderem zeitweilig in Diskussionsforen statt, durch die die Anzahl zusammengesetzter und komplexer Refactorings auf Java-Basis weiter angewachsen ist. Es ist jedoch nicht erstaunlich, dass die Anzahl der grundlegenden Refactorings sich in den letzten Jahren nicht mehr besonders verändert hat. Dies dürfte darauf zurückzuführen sein, dass grundlegende Refactorings immer nur eine sehr kleine Anzahl von Sprachkonzepten behandeln. Dementsprechend ist die Anzahl der grundlegenden Transformationen auf einer Sprache begrenzt und [Fow99] weiterhin die wesentliche Quelle für Refactorings. Das
Nachfolgend werden deshalb 68 der in [Fow99] publizierten Refactoring-Regeln in kompakter Form analysiert. Dabei wird angenommen, dass [Fow99] bekannt ist. Die vier nicht dargestellten Regeln werden dort als „Big Refactorings“ bezeichnet, die sich zum Beispiel mit der Separation komplexer Vererbungshierarchien oder dem Umbau prozeduralen Codes in Objektstrukturen beschäftigen.
Ziel dieser Analyse ist eine Klassifikation der Regeln nach zwei Kriterien: (1) Auf welche Elemente wirkt die Regel und (2) welche Auswirkungen hat sie darauf? Die sechs Spalten entsprechen den
Java-Sprachelementen Coderümpfe, Methoden einschließlich Konstruktoren, Attribute, Klassensignaturen einschließlich Interfaces, Vererbungsbeziehungen und
Assoziationen. Als Auswirkungen sind Verschieben ( ),
neu Einführen (*), Löschen (†) und Ändern (ch) in die entsprechenden Spalten eingefügt.
Der originale englische Name der in Tabelle 10.3 in alphabetischer Reihenfolge aufgelisteten Regeln wurde beibehalten. Die Tabelle spiegelt
die Veränderungen der primären Refactoring-Regel wider. Weitere Änderungen anderer Sprachelemente können sich in Sonderfällen ergeben.
),
neu Einführen (*), Löschen (†) und Ändern (ch) in die entsprechenden Spalten eingefügt.
Der originale englische Name der in Tabelle 10.3 in alphabetischer Reihenfolge aufgelisteten Regeln wurde beibehalten. Die Tabelle spiegelt
die Veränderungen der primären Refactoring-Regel wider. Weitere Änderungen anderer Sprachelemente können sich in Sonderfällen ergeben.
|
|
|
|
|
|
|
|
|
Klassifikation der Refactoring-Regeln aus [Fow99]
|
||||||
|
|
|
|
|
|
|
|
|
Name der Refactoring-Regel |
Code |
Methd. |
Attrib. |
Kl.Sig. |
Vererb. |
Assoz. |
|
|
|
|
|
|
|
|
|
Add Parameter |
ch |
ch |
ch |
|||
|
Change Bidirectional Association to Unidirectional (wird in UML/P durch Generator vereinfacht) |
ch |
† |
ch |
|||
|
Change Reference to Value |
ch |
ch |
||||
|
Change Unidirectional Association to Bidirectional (wird in UML/P durch Generator vereinfacht) |
ch |
* |
ch |
|||
|
Change Value to Reference |
ch |
ch |
||||
|
Collapse Hierarchy |
|
|
† |
† |
|
|
|
Consolidate Conditional Expression |
ch |
* |
||||
|
Consolidate Duplicate Conditional Fragments |
ch |
|||||
|
Decompose Conditional |
ch |
* |
||||
|
Duplicate Observed Data |
ch |
* |
* |
* |
* |
* |
|
Encapsulate Collection |
ch |
* |
||||
|
Encapsulate Downcast |
ch |
ch |
||||
|
Encapsulate Field (unnötig, wenn das dem Generator aufgetragen wird) |
ch |
* |
ch |
|||
|
Extract Class |
|
|
* |
* |
||
|
Extract Interface |
* |
* |
||||
|
Extract Method |
|
* |
||||
|
Extract Subclass |
|
|
* |
* |
||
|
Extract Superclass |
|
|
* |
* |
||
|
Form Template Method |
ch |
* |
ch |
|||
|
Hide Delegate |
ch |
* |
ch |
† |
||
|
Hide Method |
ch |
ch |
||||
|
Inline Class |
|
|
† |
† |
||
|
Inline Method |
|
† |
||||
|
Inline Temp |
ch |
|||||
|
Introduce Assertion (in UML/P gibt es dazu erweiterte Möglichkeiten) |
ch |
|||||
|
Introduce Explaining Variable |
ch |
|||||
|
Introduce Foreign Method |
ch |
* |
||||
|
Introduce Local Extension (nutzt Adapter oder Unterklasse) |
* |
* |
* |
* |
||
|
Introduce Null Object |
ch |
* |
* |
* |
||
|
Introduce Parameter Object |
ch |
ch |
* |
|||
|
Move Field |
ch |
|
||||
|
Move Method |
ch |
|
ch |
|||
|
Parameterize Method |
ch |
ch |
ch |
|||
|
Preserve Whole Object |
ch |
ch |
ch |
|||
|
Pull Up Constructor Body |
|
* |
||||
|
Pull Up Field |
|
|||||
|
Pull Up Method |
|
|||||
|
Push Down Field |
|
|||||
|
Push Down Method |
|
|||||
|
Remove Assignments to Parameters |
ch |
|||||
|
Remove Control Flag |
ch |
|||||
|
Remove Middle Man |
ch |
† |
ch |
* |
||
|
Remove Parameter |
ch |
ch |
ch |
|||
|
Remove Setting Method |
† |
ch |
||||
|
Rename Method |
ch |
ch |
||||
|
Replace Array with Object |
ch |
* |
||||
|
Replace Conditional with Polymorphism |
ch |
* |
* |
|||
|
Replace Constructor with Factory Method (unnötig, wenn das dem Generator aufgetragen wird) |
ch |
* |
ch |
|||
|
Replace Data Value with Object |
ch |
ch |
* |
* |
||
|
Replace Delegation with Inheritance |
ch |
† |
ch |
* |
† |
|
|
Replace Error Code with Exception |
ch |
ch |
||||
|
Replace Exception with Test |
ch |
|||||
|
Replace Inheritance with Delegation |
ch |
* |
ch |
† |
* |
|
|
Replace Magic Number with Symbolic Constant |
ch |
* |
||||
|
Replace Method with Method Object |
ch |
* |
* |
* |
* |
|
|
Replace Nested Conditional with Guard Clauses |
ch |
|||||
|
Replace Parameter with Explicit Methods |
ch |
* |
ch |
|||
|
Replace Parameter with Method |
ch |
ch |
ch |
|||
|
Replace Record with Data Class (für UML/P uninteressant) |
* |
|||||
|
Replace Subclass with Fields |
ch |
ch |
† |
† |
||
|
Replace Temp with Query |
|
* |
||||
|
Replace Type Code with Class |
ch |
† |
* |
|||
|
Replace Type Code with State/Strategy (sinnvoll ist auch die Nutzung eines Statecharts) |
ch |
† |
* |
* |
* |
|
|
Replace Type Code with Subclasses |
ch |
† |
* |
* |
||
|
Self Encapsulate Field (unnötig, wenn das dem Generator aufgetragen wird) |
ch |
* |
||||
|
Separate Query from Modifier |
ch |
* |
ch |
|||
|
Split Temporary Variable |
ch |
|||||
|
Substitute Algorithm |
ch |
|||||
|
|
|
|
|
|
|
|





















Weil in fast allen Refactoring-Regeln die Klasse, die die modifizierten, eingeführten oder entfernten Elemente enthält, betroffen ist, wird die entsprechende Spalte nur markiert, wenn der extern bekannte (public) Anteil der Methoden einer Modifikation unterliegt.
Im Gegensatz zu allen anderen Regeln beschreibt das Refactoring „Encapsulate Collection“ den Umgang mit Container-Klassen und ist damit abhängig von der Java-Klassenbibliothek. Dieses Beispiel zeigt, dass nicht nur auf der Sprache, sondern auch auf den Klassenbibliotheken operierende Refactoring-Regeln sinnvoll sind.
Wie sich aus der Tabelle erkennen lässt, werden bei vielen Refactorings aus [Fow99] mehrere Schritte zusammengefasst. So wird bei der Expansion einer Methode mit „Inline Method“ gleichzeitig vorgeschlagen, diese zu löschen. Dies hat zur Nebenbedingung, dass die expandierte Methode sonst nirgendwo verwendet wird, und hätte auch in zwei unabhängige Refactorings zerlegt werden können.
Die Granularität vieler Regeln, wie „Form Template Method“ zur Extraktion einer Methode in eine Oberklasse, die in mehreren Unterklassen ähnlich realisiert ist, ist so gewählt, dass sie zielgerichtete Vorgehensweisen zur Verbesserung der Aufrufstruktur von Methoden beinhalten. Derartige Regeln nutzen oft andere Regeln, wie hier zum Beispiel die Verschiebung von Methoden in der Klassenhierarchie. Die Refactoring-Regeln in [Fow99] sind oft nicht minimal, sondern kombinieren einzelne Transformationen zu einer zielgerichteten Vorgehensweise. Die bei der Behandlung des Codes oft notwendigen algebraischen Umformungen werden dabei nicht explizit diskutiert, sondern stillschweigend deren Beherrschung vorausgesetzt.
Übertragung der Refactorings auf UML/P
Für die Erstellung von Transformationsregeln lassen sich mehrere Ansätze identifizieren. Beispielsweise lassen sich Transformationsregeln aus der in Abbildung 9.5 dargestellten Theorie motivieren. Dabei wird die vorhandene Sprache untersucht und äquivalente beziehungsweise in Verfeinerung stehende Darstellungen eines Sachverhalts identifiziert. Demgegenüber können Transformationsregeln für eine neue Sprache durch eine Adaption von Regeln einer bereits bekannten Sprache entstehen. Dazu kann die in Abbildung 10.4 dargestellte Vorgehensweise angewandt werden.
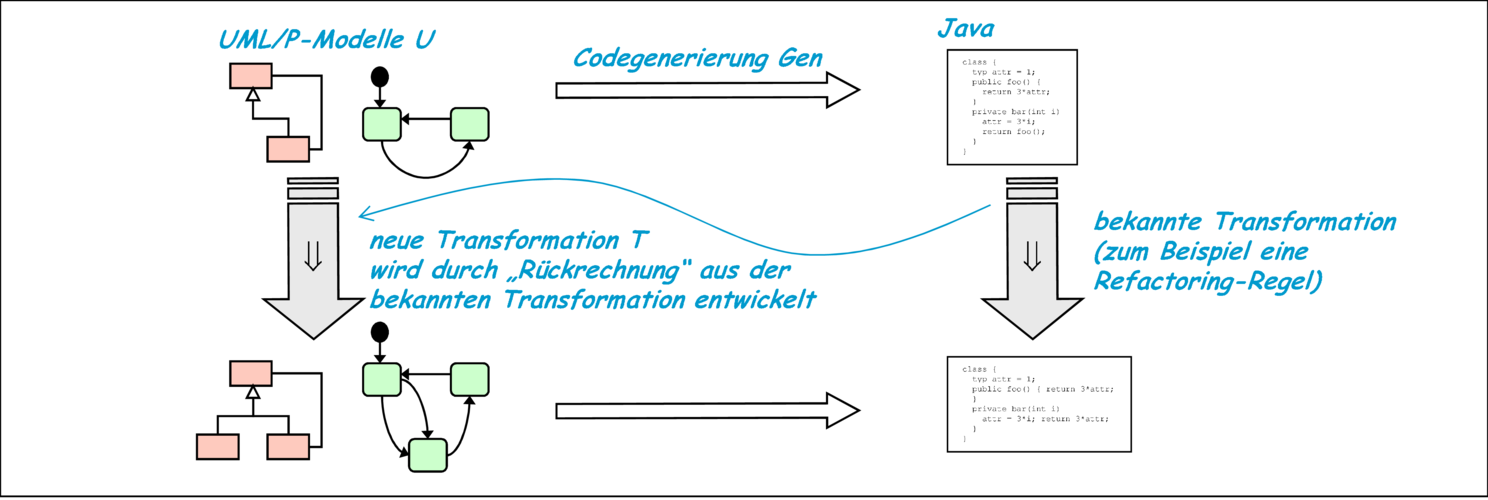
Die in [Fow99] enthaltenen Refactorings für Java können dadurch auf UML/P übertragen werden. Grundlage dazu ist die in Kapitel 4 diskutierte Codegenerierung als Verbindung zwischen UML/P und Java. Die auf Java existierenden Refactoring-Regeln können mithilfe dieser Codegenerierung auf UML/P übersetzt werden. Dabei können allerdings manche Regeln obsolet werden, wie bereits in der Tabelle 10.3 vermerkt. Andere Regeln finden mehrere Ausprägungen. Diese Rückrechnung der Transformationsregeln auf UML/P wird umso komplexer, je größer der konzeptuelle Unterschied zwischen beiden Sprachen ist. Bei Klassendiagrammen und Java ist dieser sehr gering und die Rückrechnung daher weitgehend kanonisch. Statecharts und Java haben jedoch einen so großen konzeptuellen Abstand, dass für Statecharts ganz eigenständige Transformationsregeln sinnvoll sind.
Da OCL und Java viele Sprachkonzepte gemeinsam haben, lassen sich eine Reihe der in [Fow99] beschriebenen Refactoring-Regeln auf die OCL übertragen. In der OCL werden zum Beispiel temporäre Variablen mit dem let-Konstrukt definiert. Diese können ebenfalls expandiert oder umgeformt werden. Die Extraktion von neuen Methoden wird in der OCL mithilfe der Definition von Queries im zugrunde liegenden Klassendiagramm durchgeführt. Zum Beispiel kann die Regel „Inline Temp“, die eine temporär benutzte Variable expandiert, durch folgende Regel beschrieben werden:

Dabei wird jedes Vorkommen der Variable temp im Ausdruck expr2 durch den Teilausdruck expr substituiert. In der OCL sind wie zum Beispiel hier aufgrund der Seiteneffektfreiheit und Determiniertheit viele Kontextbedingungen von vornherein erfüllt.
Andere Regeln modifizieren die Struktur oder die Signatur von Klassen oder fügen neue Klassen ein. Diese Regeln können daher in adäquater Weise ebenfalls auf Klassendiagrammen (und den davon abhängigen Java/P-Coderümpfen) eingesetzt werden. Allerdings ist der Regelsatz auch hier keineswegs vollständig. So existiert mit „Hide Method“ eine Regel, eine öffentliche Methode in eine private umzuwandeln, aber die Umkehrung ist so einfach, dass diese nicht durch eine Regel abgedeckt wurde. Weitere Regeln können zum Beispiel die Umwandlung einer Klasse in ein Interface oder die Modifikation beigefügter Stereotypen behandeln.
Regeln, die die Signatur einer Methode oder eines Attributs verändern, haben auch Auswirkungen auf die Stellen in Tests, Statecharts oder Sequenzdiagrammen, in denen diese Elemente genutzt werden. Ein für einen Test eingesetztes Sequenzdiagramm ist zum Beispiel anzupassen, wenn sich die innere Aufrufstruktur ändert und Stereotypen wie ≪match:complete≫ dies in einem Sequenzdiagramm erfordern (siehe Abschnitt 6.3, Band 1).
10.1.3 Refactoring von Klassendiagrammen
Im vorangegangenen Abschnitt 10.1.2 wurden im Kontext von Java/P bereits eine Reihe von Refactoring-Regeln identifiziert, die Klassen modifizieren und damit auch auf Klassendiagramme Auswirkungen haben. Es gibt jedoch weitere Refactoring-Regeln für Klassendiagramme. Die Regeln für die Transformation von Klassendiagrammen lassen sich in folgende Kategorien einteilen:
- Kleine Refactorings
- dienen der Bearbeitung eines einzelnen Elements im Klassendiagramm. Dazu gehörten zum Beispiel das Löschen oder Einfügen eines Attributs.
- Zielgerichtete, mittelgroße Refactorings
- sind Transformationsschritte, die eine Motivation und ein Ziel beinhalten. Diese Form der Refactoring-Schritte wurde bereits in Abschnitt 10.1.2 für Java diskutiert und tangiert meistens mehrere Elemente auch außerhalb eines einzelnen Modells. Diese Regeln sind aber in ihren Auswirkungen lokal begrenzt.
- Verbesserung der Repräsentation
- dient zur besseren Darstellung eines Sachverhalts, ohne dabei eine inhaltliche Änderung vorzunehmen. Dazu gehört zum Beispiel die Reorganisation von Klassendiagrammen.
- Abstrakte Klassendiagramme
- können als Beschreibungen von Schnittstellen und Komponenten eingesetzt werden. Ein solches Klassendiagramm enthält nur den Teil der Datenstruktur und Methoden, die explizit publiziert wurden und damit gesichert zur Verfügung stehen. Ein solches Klassendiagramm wird durch Abstraktionsschritte aus der internen Struktur gewonnen.
Diese Kategorien von Transformationstechniken werden nun im Einzelnen diskutiert.
Kleine Refactorings
Viele Transformationsregeln bestehen nur aus der Transformation eines einzelnen syntaktischen Elements. Die Syntax von Klassendiagrammen wird in Anhang C, Band 1 beschrieben und besteht aus 19 Nichtterminalen. Für jedes Nichtterminal kann ein neues Element eingeführt, ein Bestehendes gelöscht oder dessen Bestandteile modifiziert werden. Dazu gehören zum Beispiel Umbenennung eines Attributs, einer Assoziation oder Rolle, Verschärfung einer Kardinalität, Modifikation einer Sichtbarkeitsangabe, Veränderung einer Navigationsrichtung, Einführung oder Elimination eines Qualifikators und Ersetzung des Typs einer Variable. Weil diese auf ein syntaktisches Element fokussierenden Modifikationen aber relativ klein und kanonisch anwendbar sind, wird hier auf eine Auflistung dieser Refactorings verzichtet. Allerdings besitzen einige dieser Modifikationen Kontextbedingungen oder erfordern weitere Aktivitäten an den benutzenden Stellen.
Mittlere und große Refactorings sind zielgerichtet und aus der Erfahrung praktischer Anwendung definiert. Sie modifizieren meistens mehrere Elemente und unter Umständen sogar einen signifikanten Teil der Applikation.
Zielgerichtete Refactorings
Wie die Tabelle 10.3 zeigt, tangieren die in [Fow99] beschrieben Regeln meistens mehrere Elemente und kombinieren zielgerichtete Strategien zur Verbesserung des Designs. Zum Beispiel könnte die Migration eines Attributs im Prinzip in die Einzelschritte (1) neues Attribut einführen, (2) die Modifikation der verwendenden Stellen und (3) altes Attribut löschen, zerlegt werden. Erst durch die Kombination dieser Einzelschritte entsteht aber eine zielgerichtete Strategie.
Dennoch besitzt die Regel zur Migration von Attributen in [Fow99] ein Defizit in ihrer Umsetzung, die zum Beispiel durch die Verwendung von Invarianten behoben werden kann. Dieses Defizit besteht darin, dass sichergestellt werden muss, dass ein eindeutiger Navigationspfad zwischen der alten und der neuen Klasse des Attributs existieren muss, der keinen zeitlichen Veränderungen unterliegt.
Die nachfolgend demonstrierte Migration eines Attributs zwischen zwei Klassen ist ein einfaches Beispiel für das Zusammenspiel mehrerer UML/P-Notationen, das über ein Klassendiagramm koordiniert werden kann.
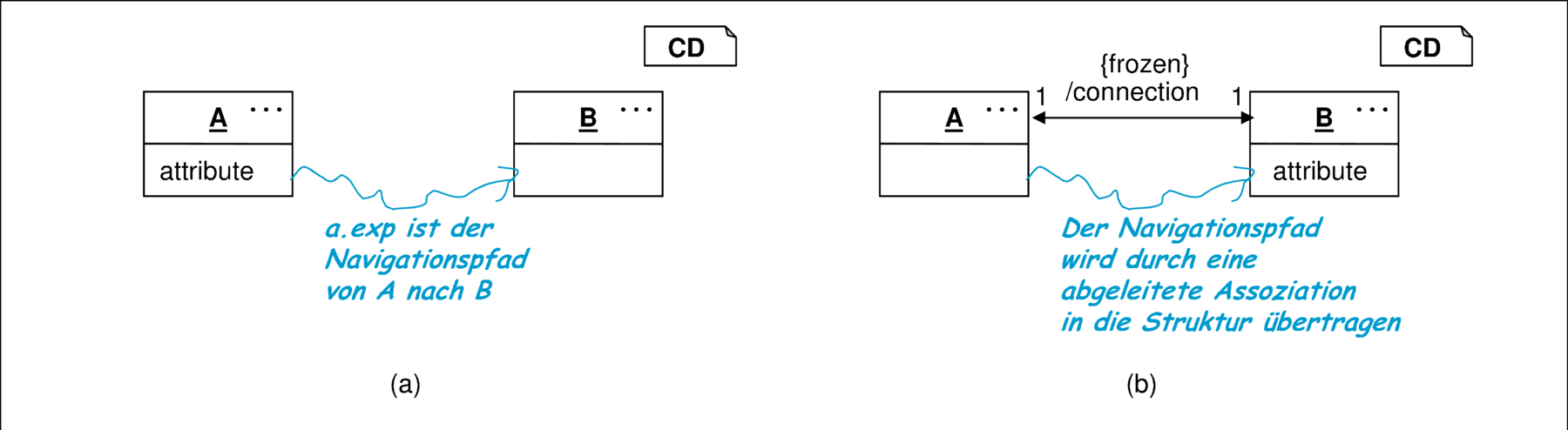
Einfache Sonderfälle dieser Migration sind, dass die neue Klasse eine Oberklasse darstellt oder das Attribut statisch ist und damit nur einmal existiert. Im allgemeinen Fall jedoch gibt es zwei Klassen, deren Objekte über einen möglicherweise komplexen Navigationspfad miteinander verbunden sind. Ausgehend von der in Abbildung 10.5(a) dargestellten Situation soll das angegebene Attribut von A nach B verschoben werden.
OCL  context A a inv Connect: context A a inv Connect: |
| a.connection == a.exp |
OCL  context A a1, A a2 inv Unique: context A a1, A a2 inv Unique: |
| a1 != a2 implies a1.connection != a2.connection |
Dabei ist einerseits zu beachten, dass zwischen den Objekten beider Klassen eine geeignete Beziehung herrscht. Dies kann meist dadurch repräsentiert werden, dass es einen Ausdruck a.exp für jedes Objekt a:A gibt, der eindeutig zu Objekten der Klasse B führt. Dieser Ausdruck kann komplexe Navigationspfade und Methodenaufrufe enthalten, besitzt aber keine Seiteneffekte. Durch die in Abbildung 10.5(b) dargestellte abgeleitete Assoziation connection und die OCL-Bedingung Connect wird dieser Ausdruck in die Struktur des Klassendiagramms übernommen und so einer leichteren Bearbeitung zugänglich gemacht. Insbesondere reicht es nun aus, das Merkmal {frozen} auf die abgeleitete Assoziation anzuwenden, um sicherzustellen, dass die Objekte der Klasse B nicht ausgetauscht werden. Dies würde sonst bedeuten, dass so das ausgelagerte Attribut implizit seinen Inhalt wechseln würde.
Zum anderen ist sicherzustellen, dass jedes A-Objekt weiterhin sein eigenes Attribut besitzt. OCL-Bedingung Unique fordert dementsprechend, dass jedem A-Objekt ein eigenes B-Objekt zugeordnet ist.
Die erarbeiteten Bedingungen wirken als Kontextbedingungen für die Übertragung eines Attributs in eine andere Klasse. Das Ergebnis lässt sich in der Refactoring-Regel in Tabelle 10.6 zusammenfassen.
|
|
|
|
Refactoring: Migration eines Attributs
|
|
|
|
|
|
Problem |
Ein Attribut gehört inhaltlich zu einer anderen Klasse. Das Attribut wird mit jedem Objekt neu angelegt und die Klassen stehen nicht in Vererbungsbeziehung. |
|
|
|
|
Ziel |
Das Attribut wird zwischen zwei Klassen verschoben. |
|
|
|
|
Motivation |
Wenn das Attribut eher von der anderen Klasse genutzt wird, empfiehlt es sich das Attribut dorthin zu verschieben. |
|
|
|
|
Refactoring |
|
|
|
|
|
|
|
|
Sonderfälle |
Ist das Attribut statisch oder wird es entlang der Vererbungshierarchie nach oben verschoben, so entfällt die Assoziation. |
|
|
|
|
Beachtenswert |
Es sind Verallgemeinerungen möglich, wenn sich zum Beispiel mehrere A-Objekte mit gleichen Attributinhalten ein gemeinsames B-Objekt teilen. |
|
|
|
|
Tabelle 10.6.: Refactoring: Migration eines Attributs
|
|
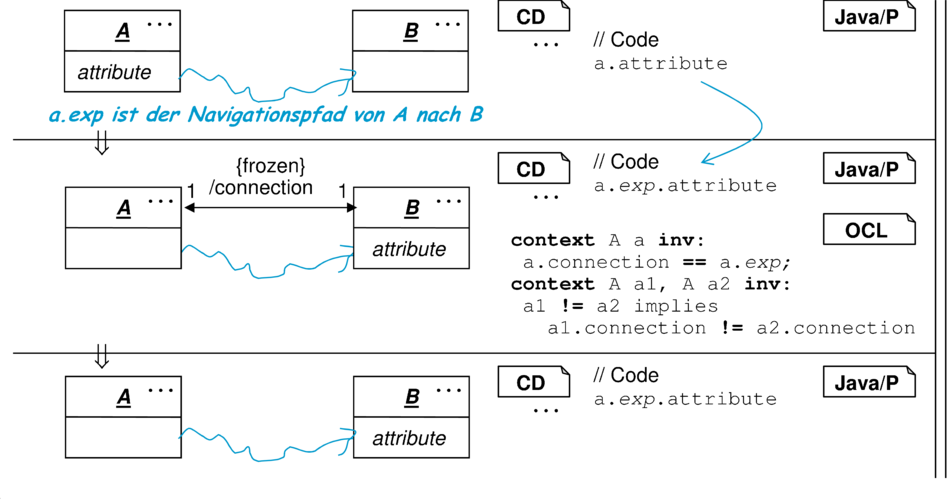
Wie in der Refactoring-Regel demonstriert, können Invarianten am Ende des Refactorings beziehungsweise in einer nachfolgenden Weiterentwicklung des Systems aufgegeben werden. Dies ist zum Beispiel notwendig, wenn es das Ziel dieses Refactorings ist, den Austausch des Attributinhalts attribute in Zukunft durch Umhängen von B-Objekten zu bewerkstelligen.
Die zeitliche Fixierung des Navigationspfads von Klasse A zu Klasse B wird in der Literatur gerne übergangen und lässt sich in Java selbst auch nicht ohne Aufwand darstellen. Die UML/P ist aufgrund ihrer syntaktischen Reichhaltigkeit dafür deutlich besser geeignet.
Verbesserung der Präsentationsform durch Refactoring
Wie bereits in Abschnitt 2.4, Band 1 diskutiert, ist die Beziehung zwischen Modell und Implementierung vielschichtig. So können syntaktisch unterschiedliche Modelle semantisch identisch sein und bei ihrer Übersetzung in Code zum gleichen System führen. Die Unterschiede der Modelle beziehen sich daher nur auf ihre Darstellung, nicht aber auf die Implementierung. [MRR11] beschreibt dazu passende Algorithmen um semantisch äquivalente Modelle zu erkennen bzw. ihre semantischen Unterschiede darzustellen.
Ein Standardbeispiel für äquivalente Modelle ist die in Abschnitt 2.4, Band 1 diskutierte Verschmelzung von Klassendiagrammen, die aus zwei oder mehr Teildiagrammen ein Gesamtmodell entwickelt, das dieselbe Information beinhaltet.
Die Migration von Information aus einem Klassendiagramm in ein anderes oder die Spaltung von Klassendiagrammen sind dazu verwandte Schritte, die während der Entwicklung vorgenommen werden. Eine Spaltung bietet sich zum Beispiel an, wenn durch wiederholtes Hinzufügen von Funktionalität und Struktur in Form neuer Klassen, Methoden und Attribute ein Klassendiagramm überladen wurde. Ebenso ist eine Spaltung von Interesse, wenn sich der im Diagramm dargestellte Systemausschnitt in zwei relativ unabhängige Subsysteme gliedern lässt, die im weiteren Verlauf des Projekts von unabhängigen Entwicklerteams bearbeitet werden sollen.
Auch die Migration von Klassen zwischen Diagrammen dient zur Verbesserung der Darstellungsform des Modells. Detailinformation zu einzelnen Klassen, wie zum Beispiel Attribute oder Methoden, können zwischen Diagrammen migriert werden, wenn die Diagramme überlappende Anteile besitzen.
Wichtig ist es hier, den Unterschied zwischen der Migration eines Attributs oder einer Methode von einer Klasse in eine andere und der Migration der Information zwischen Klassendiagrammen zu unterscheiden. Im Beispiel bleiben Attribute und Methoden in derselben Klasse und werden nur an anderer Stelle dargestellt.
Eine weitere Form der Bearbeitung von Klassendiagrammen ist zum Beispiel die Expansion der Detailinformation von Klassen. So kann in einem Diagramm die aus anderen Diagrammen verfügbare Information zusätzlich dargestellt werden, ohne diese Information an anderer Stelle zu entfernen.
Die diskutierten Beispiele demonstrieren, dass Refactoring nicht nur zur Verbesserung der Systemstruktur eingesetzt werden kann, sondern auch, um die Präsentationsform der Strukturen eines Systems anders darzustellen. Dieses Phänomen ist in manchen der in [Fow99] diskutierten Refactorings ebenfalls zu beobachten, wenn zum Beispiel vorgeschlagen wird, den Namen einer Methode so zu ändern, dass er deren Aufgabe inhaltlich besser beschreibt. Refactorings haben dort aber oft gleichzeitig Auswirkungen auf Präsentation und Struktur. So verbessert die Aufteilung einer Klasse deren Präsentation dem Entwickler gegenüber, modifiziert aber auch die Struktur des Systems.
Die syntaktische Reichhaltigkeit der UML/P ist einer der Gründe für den gesteigerten Bedarf an einer Verbesserung der Darstellung von Modellen. Während sich in der Programmiersprache Java, die Variabilität des Quellcodes auf die Reihenfolge der dargestellten Methoden und Attribute, Einrückungen, algebraisch äquivalente Umformungen von Ausdrücken und dergleichen beschränkt, lassen sich in der UML/P mehr Varianten für die Darstellung desselben Sachverhalts finden. Das liegt zum Beispiel darin begründet, dass die Definitionsstellen für Attribute und Methoden nicht eindeutig festgelegt sind, sondern sich in verschiedenen Klassendiagrammen befinden können. Auch für OCL-Bedingungen lassen sich im Allgemeinen eine Reihe semantisch äquivalenter Darstellungen finden. Zum Beispiel können die Hierarchie, die Transitionen und die Zustände in Statecharts durch die in Abschnitt 5.6.2, Band 1 eingeführten Regeln manipuliert werden.
Einsatz abstrakter Klassendiagramme zur Schnittstellendefinition
Die syntaktische Reichhaltigkeit der UML/P bietet einerseits den Vorteil, dass die für jede Situation adäquate, kompakte Darstellungsform gewählt werden kann, führt aber andererseits zu dem hier sichtbaren Problem, dass dadurch zum Beispiel die Definitionsstelle für ein Attribut schwerer auffindbar und daher gute Werkzeugunterstützung notwendig ist. Dieses Problem muss durch einen geeigneten Modellierungsstandard geregelt werden. Beispielsweise hat es sich als hilfreich erwiesen, jeweils ein detailliertes Klassendiagramm für jedes nicht weiter untergliederte Subsystem zu verwenden, in dem alle Attribute und Methoden mit ihren Signaturen aufgelistet werden. Weitere Klassendiagramme werden eingesetzt, um Zusammenhänge zwischen Subsystemen darzustellen. Diese enthalten nur eine Teilmenge der existenten Klassen und Assoziationen und vernachlässigen meistens Detailinformation. Ein Klassendiagramm kann auch, wie in [HRR98] diskutiert, als Schnittstelle für die von außen zugänglichen Anteile einer Komponente eingesetzt werden. Ein solches Klassendiagramm stellt dann ebenfalls eine Abstraktion des tatsächlichen Modells der Komponente dar, die für einen Entwickler ausreicht, um die Komponente einzusetzen.
Die verschiedenen Formen von Klassendiagrammen können durch systematische Manipulationen, die ebenfalls als Refactoring-Schritte bezeichnet werden können, auseinander hergeleitet werden. So lassen sich dafür Techniken zur Verschmelzung von Diagrammen, Migration oder Expansion von Detailinformation und in umgekehrter Richtung die Entfernung redundant vorhandener Information einsetzen. Wesentlich ist aber, dass insbesondere bei Klassendiagrammen die Einsatzform durch geeignete Stereotypen kenntlich gemacht wird. Hier eignen sich zum Beispiel die Repräsentationsindikatoren „©“ und „…“ zur Anzeige, ob die dargestellte Detailinformation vollständig oder unvollständig ist.
Aus pragmatischen Gründen sollte aber auch versucht werden, die Redundanz zwischen verschiedenen Repräsentationen desselben Sachverhalts möglichst gering zu halten. Redundanz führt häufig zu Inkonsistenzen, wenn ein Teil des Systems zum Beispiel durch Refactoring-Schritte modifiziert wird und kein Werkzeug eingesetzt werden kann, um diese Konsistenz automatisch zu sichern. Redundanz führt dann zu erhöhtem Änderungsaufwand. Andererseits ist geschickt eingesetzte Redundanz ein wesentliches Mittel zur Durchführung von Konsistenztests. Dazu gehören die Redundanz zwischen Testmodell und Implementierung, aber zum Beispiel auch ein als Schnittstelle einer Komponente bekannt gegebenes („publiziertes‘’) Klassendiagramm, das eine Abstraktion der Implementierung darstellt und mit dieser konsistent sein muss.
10.1.4 Refactoring in der OCL
Weil die OCL seiteneffektfrei und determiniert ist, existiert ein breites Angebot an Umformungen, die auf OCL-Aussagen angewandt werden können. Zu diesen Umformungen gehören Beispiele aus Abschnitt 9.1 oder Gesetze im Umgang mit Containern, wie etwa:

Neben den algebraischen Umformungen sind vor allem die Gesetze der Logik wesentlich, um OCL-Aussagen zu modifizieren. Typisch sind etwa die Gesetze der booleschen Logik wie zum Beispiel die Kommutativität:

Da die OCL in den Kontext der UML eingebettet ist, können viele Aussagen nur durch Bezug auf die zugrunde liegenden Modelle formuliert werden. Wir nehmen an, es sei festgelegt, dass es genau ein Objekt der Klasse AllData gibt, und dass dieses mit AllData.ad zugänglich ist. Deshalb ist unter dieser Kontextbedingung folgende Transformation möglich:

Wie bereits in Abschnitt 9.3.6 diskutiert, hat die Mathematik eine lange Tradition in der korrekten Umformung von Aussagen. Durch Logik-Kalküle und algebraische Systeme wurden diese Transformationstechniken weiter verfeinert und präzisiert. Heute existieren verschiedene Werkzeuge, die eine präzise Manipulation von Formeln erlauben. Dazu gehört zum Beispiel der auf HOL basierende Theorembeweiser [NPW02] oder das KIV-System [Rei99]. Eine Einbettung der OCL in HOL, wie dies in [BW02a, BW02b] diskutiert wurde, erlaubt die Transformation der OCL-Aussagen in HOL und macht den dort zur Verfügung stehenden Verifikationsapparat auf OCL anwendbar.
Tatsächlich bilden die Refactoring-Regeln auf der OCL einen Logik-Kalkül für die OCL. Die für eine Logik übliche Präzision der Kontextbedingungen ist dabei sehr hilfreich, wenn die Anwendung der Regeln mit automatisierten Werkzeugen unterstützt werden soll. Auf der Syntax automatisiert prüfbare Kontextbedingungen können entsprechend von einem Werkzeug übernommen werden. Für die nicht automatisiert prüfbaren Kontextbedingungen können mehrere Strategien eingesetzt werden:
- Die Kontextbedingungen werden informell auf Plausibilität geprüft. Die Korrektheit der Transformation ist damit nicht sichergestellt. Allerdings handelt es sich bei den Bedingungen zumeist um Invarianten, die in Tests eingesetzt werden können. Damit besteht die Chance, dass eine fehlerhaft transformierte Invariante durch einen fehlerhaften Test erkannt wird. Die Wahrscheinlichkeit, dass dies geschieht ist allerdings relativ gering, da eine „Überdeckung“ der verschiedenen Alternativen einer Invariante durch Tests im Allgemeinen nicht vorliegt. Dennoch ist diese pragmatische Vorgehensweise für verschiedene Projekttypen ausreichend.
- Deutlich verbessert wird die Situation, wenn zusätzliche Tests eingesetzt werden, um die Korrektheit einer Kontextbedingung zu prüfen. Das bedeutet, dass die in OCL formulierte Kontextbedingung einer Transformation für die Anwendungsstelle selbst als Invariante angesehen und vorübergehend in den Code eingefügt wird. Durch das Vorhandensein einer guten Testsammlung beziehungsweise den Aufbau weiterer geeigneter Tests wird die Plausibilität der Kontextbedingung deutlich besser geprüft. Da die Tests selbst automatisch ablaufen und daher effizient eingesetzt werden können, bedeutet dies nicht sehr viel Zusatzaufwand und ist daher zumindest für kritische oder nicht ganz klare Kontextbedingungen sinnvoll.
- Die Verifikation der Kontextbedingungen bietet Sicherheit für die Korrektheit der Transformation, ist aber üblicherweise nicht durchführbar oder zu aufwändig.
Das vorgeschlagene Verfahren, Kontextbedingungen durch Tests zu prüfen, wird in Abschnitt 10.2 ausgebaut, um damit Datenstrukturwechsel vorzunehmen.
Die OCL ist als Spezifikationssprache im Kontext anderer UML-Diagramme konzipiert. Auch deshalb bietet die OCL nur wenig Unterstützung für Verifikationstechniken und es bietet sich an in der Praxis die beiden zuerst genannten Verfahren einzusetzen.
10.1.5 Einführung von Testmustern als Refactoring
In Kapitel 8 wurden mehrere Muster beschrieben, die ein System besser für die Definition von Tests zugänglich machen. Diese Muster wurden in Ergebnisform präsentiert, indem die gewünschte Struktur dargestellt wurde. Oft ist das zu testende System jedoch bereits in anderer Form vorhanden und muss geeignet adaptiert werden, um Tests effektiv definieren zu können. Es bietet sich daher an, das System mit geeigneten Refactoring-Regeln so zu transformieren, dass es danach die vom Testmuster vorgeschlagene Struktur enthält.
Die folgende Refactoring-Regel führt die in Tabelle 8.9 diskutierte Struktur ein, um eine statische Methode für die Testumgebung adaptierbar zu machen. Dabei wird von einer gegebenen statischen Methode ausgegangen und diese in ein Singleton gekapselt.
|
|
|
|
Refactoring: Statische Methoden für Tests adaptierbar machen
|
|
|
|
|
| Problem | Statische Methoden sind für Tests unzugänglich, da sie nicht durch Dummies überschrieben werden können. |
|
|
|
| Ziel | ist es, die Funktionalität einer statischen Methode an ein Objekt zu delegieren, das für Tests durch ein Dummy ersetzt werden kann, aber eine öffentlich zugängliche statische Variable zu vermeiden, die dieses Objekt beinhaltet. |
|
|
|
| Motivation | Siehe Tabelle 8.9 zur Beschreibung des Testmusters. |
|
|
|
| Refactoring Teil 1 | 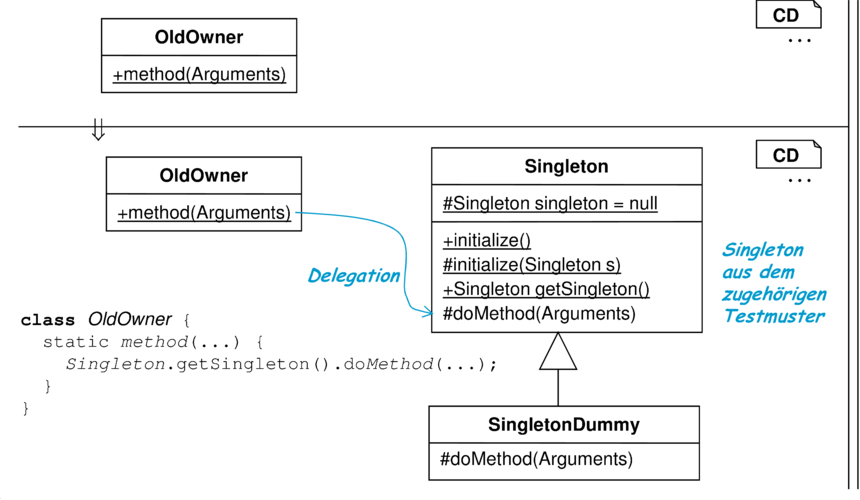 |
|
|
|
|
|
|
|
|
| Refactoring Teil 2 | 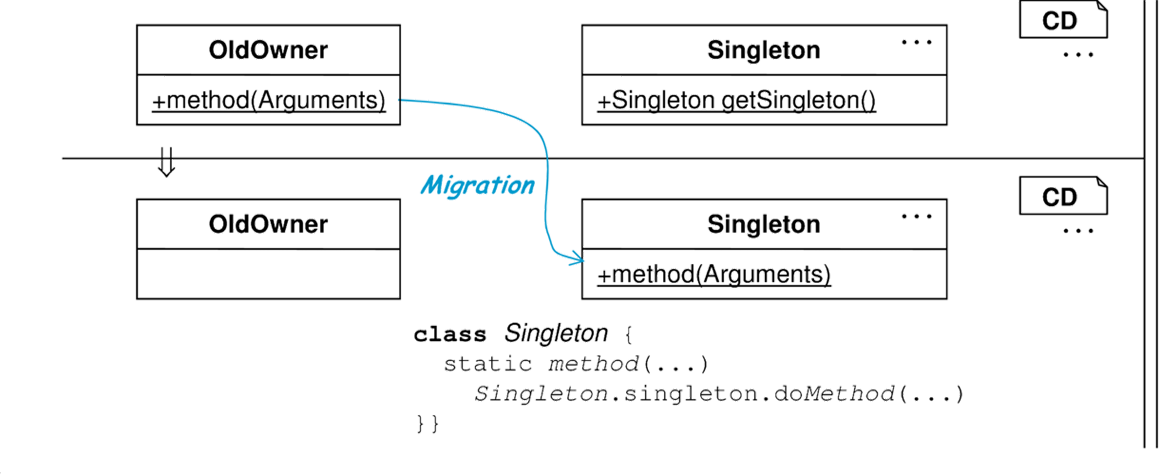 |
|
|
|
|
|
| Implementierungen | Die Implementierungen der einzelnen Methoden sind in Tabelle 8.9 zu finden. |
|
|
|
| Beispiele | Diese Transformation wurde im Auktionssystem unter anderem verwendet, um den Datenbankanschluss und die Protokollierung zu kapseln (siehe auch Abbildung 8.8). |
|
|
|
| Beachtenswert | Die Regel wurde in zwei Teile unterteilt, da der erste Teil eigenständig eingesetzt werden kann. Dies empfiehlt sich, wenn das Singleton öffentlich zugänglich bleiben soll. |
| Wenn die Klasse OldOwner keine weiteren Aufgaben hat, so kann diese statt der neu eingeführten Singleton-Klasse direkt verwendet werden. | |
| Verwandt mit dieser Refactoring-Regel ist die Kapselung statischer Variablen und die Definition von Methoden zu deren Zugriff und Manipulation. | |
|
|
|
|
Tabelle 10.8.: Refactoring: Statische Methoden für Tests adaptierbar machen
|
|
Da dieses Muster und ein Anwendungsbeispiel bereits in Abschnitt 8.2.1 diskutiert wurden, werden statt einer vollständigen Darstellung der Refactoring-Regel vereinzelt Verweise angegeben.
Die anderen in Kapitel 8 definierten Testmuster lassen sich ähnlich zu der obigen Refactoring-Regel darstellen. Exemplarisch wird dies in Tabelle 10.9 an der in Abschnitt 8.2.4 diskutierten Trennung der Applikation von Frameworks in Regelform vorgeführt. Dabei wird wieder auf die ausführlichere Diskussion in Abschnitt 8.2.4 verwiesen.
|
|
|
|
Refactoring: Applikation von Frameworks entkoppeln
|
|
|
|
|
| Problem, Ziel und Motivation | Wie in Abschnitt 8.2.4 beschrieben, ist ein Framework im Allgemeinen nicht für Tests adaptierbar. Um die Applikation testbar zu machen, werden Applikation und Framework durch eine Adapter-Schicht entkoppelt. Weitere Vorteile dieser Technik sind in [SD00] zu finden. |
|
|
|
| Refactoring | 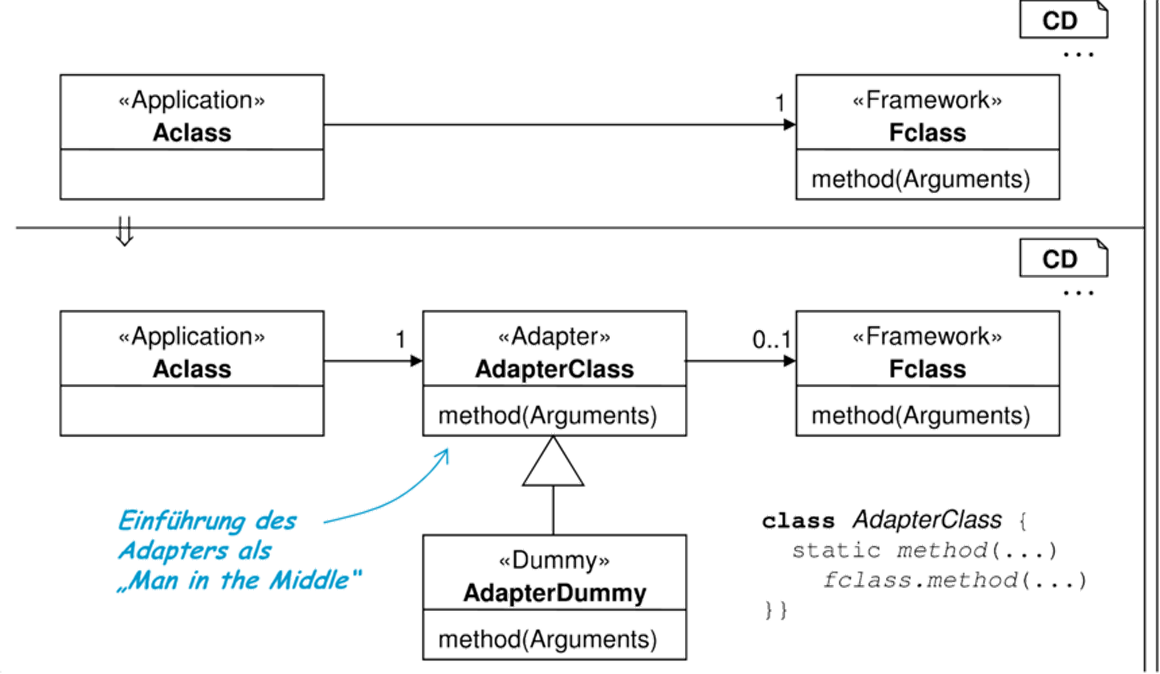 |
|
|
|
|
|
| Adapter- Management |
Die Migration der Signaturen von Adaptern kann, wie in Abbildung 8.12 gezeigt, zu Schwierigkeiten führen:
|
|
|
|
| Beispiele | Besonders bei Frameworks mit eigenem Kontrollfluss wie etwa JSP empfehlenswert. Abschnitt 8.2.4 diskutiert ein solches Beispiel. |
|
|
|
| Beachtenswert | Siehe dazu die Diskussion in Abschnitt 8.2.4 . |
|
|
|
|
Tabelle 10.9.: Refactoring: Applikation von Frameworks entkoppeln
|
|
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |