Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
4.1 Konzepte der Codegenerierung
4.2 Techniken der Codegenerierung
4.3 Semantik der Codegenerierung
4.4 Flexible Parametrisierung eines Codegenerators
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
4.4 Flexible Parametrisierung eines Codegenerators
In diesem Abschnitt wird zunächst die Frage nach einer geeigneten Darstellungsform für Generatoren und allgemeinen Transformationen diskutiert und dann eine kompakte Repräsentation der Effekte solcher Skripte eingeführt. Im Kapitel 5 werden die Eigenschaften dieser Skripte anhand einer exemplarischen Umsetzung der UML/P-Konstrukte demonstriert. Die hier diskutierten Konzepte stellen for allem Bezug zu einem Codegenerator her, sind aber auf andere Formen von Analysewerkzeugen und Transformatoren ebenfalls anwendbar. Zum Beispiel können damit auch Datenstrukturwechsel oder Refactoring-Techniken beschrieben werden.
4.4.1 Implementierung von Werkzeugen
In Abschnitt 4.2.3 wird die Verwendung von Skripten bzw. Templates zur flexiblen Parametrisierung eines Codegenerators, aber auch für Analyse- und Testwerkzeuge diskutiert. Tatsächlich erfordert eine plattformspezifische und eine auf verschiedene Implementierungsmöglichkeiten ausgerichtete Codegenerierung einen flexiblen Mechanismus zur Steuerung der Codegenerierung. Die Generierung kann im Prinzip durch Stereotypen und Merkmale gesteuert werden. Die Details des zu erzeugenden Codes können mit Stereotypen aber nicht oder zumindest nicht komfortabel festgehalten werden.
Im Allgemeinen können die zu erzeugenden Codestrukturen sehr komplex sein und unterschiedlichste Formen haben. Meist sind Symboltabellen notwendig und Nebenbedingungen zu prüfen, die die Anwendbarkeit einer Codegenerierung oder mögliche Optimierungen beschreiben. Aufgrund der erforderlichen Flexibilität kommt nur eine in ihrer Beschreibungsmächtigkeit (weitgehend) vollständige Programmiersprache in Betracht, die eine kompakte Formulierung von Bedingungen und Transformationen erlaubt. In dieser Sprache formulierte Transformationen werden vom Codegenerator zur Ausführung gebracht, um den Implementierungscode zu erzeugen. Sie sind selbst zur Laufzeit nicht vorhanden. Abbildung 4.10 beschreibt die daraus resultierende innere Struktur eines Generators.
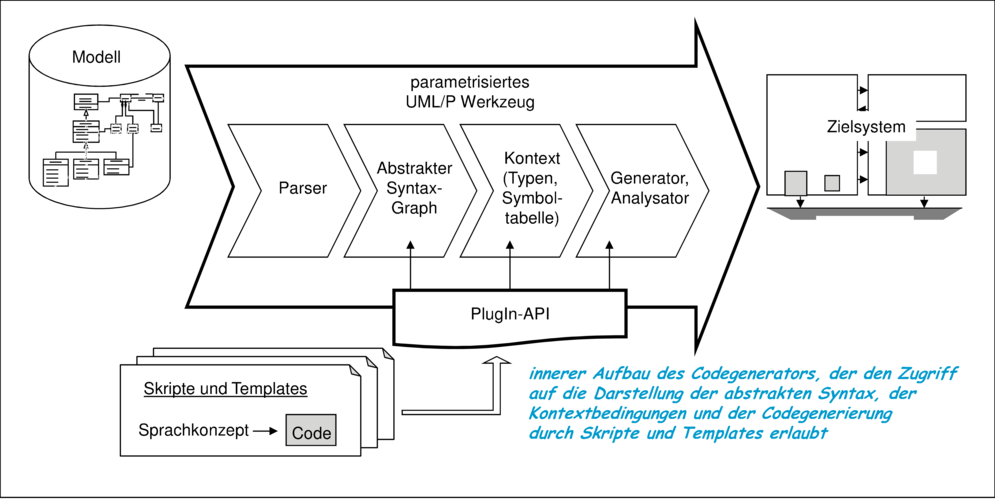
Für Skript- oder Templatesprachen wurden in der Werkzeugentwicklung unterschiedliche Vorschläge gemacht. So sind interpretierte Derivate der Sprache C ebenso in Verwendung wie Visual Basic, Skriptsprachen wie Pearl oder Tcl/Tk. Funktionale Programmiersprachen wie ML [Pau94, MTHM97] bieten darüber hinaus eine sehr kompakte Form, solche Werkzeuge zu parametrisieren. Zum Beispiel ist das Verifikationswerkzeug Isabelle [NPW02] in ML geschrieben und bietet damit gute, ebenfalls in ML zu formulierende Erweiterungsmöglichkeiten.
Eine weitere Alternative ist die mittlerweise populäre XML-Technologie [McL06, W3C00] und die Verwendung von XML/XSLT-basierten Werkzeugen zur Transformation in den Zielcode. Allerdings besitzt XML durch die explizite Einbettung der Tags (Nichtterminale) einerseits ein sehr schlechtes Verhältnis zwischen Struktur- und Nutzinformation und andererseits sind die heutigen Parse- und Transformationswerkzeuge für die XML noch nicht so leistungsfähig, wie die im Bereich des Compilerbau längst bekannten Yacc/Lex und deren Derivate.
Mit ihrer Vielzahl an Bibliotheken, Frameworks und Werkzeugen sowie der Möglichkeit des dynamischen Ladens von Klassenbibliotheken ist auch Java ein guter Kandidat, einerseits, um damit einen Codegenerator zu realisieren und andererseits, um damit die Parametrisierung über einen Plugin-Mechanismus zu ermöglichen. Beispielsweise nutzt das Werkzeug Poseidon [BS01a, BBWL01] diesen Mechanismus.
Eine aktive Skriptsprache besitzt jedoch unkomfortable Defizite bei der Komposition von Artefakten der Zielsprache. Deshalb bietet sich zusätzlich die Verwendung eines Makro-Ersetzungsmechanismus an, der Templates15 verarbeitet und daraus Code erzeugt. Ein Template ist als passive Skriptsprache zu sehen, die Makros beinhaltet, die durch den Ersetzungsalgorithmus zum Beispiel durch echte Namen oder Ausdrücke ersetzt werden. Ein Template kann aktive Elemente beinhalten, um damit Kontrollstrukturen, wie Alternative, Wiederholung oder Einbindung anderer Templates zu ermöglichen, aber auch um Berechnungen in beschränktem Maß durchzuführen. Verwendbar sind hierbei XML auf der Transformationssprache XSLT basierende Werkzeuge oder ein mit Java-Code kombinierter Template-Mechanismus ähnlich der JSP-Seiten [FK00], der zum Beispiel von [SvVB02] vorgestellt wird.
Aus der flexiblen Programmierbarkeit des Generators folgt, dass Entwickler nicht nur in der Entwicklungsprogrammiersprache, sondern in eingeschränkter Form auch in der Skriptprogrammiersprache entwickeln müssen. Aufgrund der regelmäßig notwendigen technologieabhängigen Anpassungen muss dies parallel zur eigentlichen Entwicklung geschehen und daher zumeist im selben Projekt stattfinden. Es wäre daher für das Erlernen von Vorteil, wenn sich Skript- und Zielprogrammiersprache ähnlich sind.
Im Generator-Framework MontiCore [KRV10, Kra10, KRV08, GKR+08] wird zum Beispiel die templatebasierte Java Template Engine FreeMarker [Dib01] eingesetzt, um aus UML-Modellen Code zu generieren. Die Trennung zwischen verarbeitendem Frontend (Parser und Analyse der Kontextbedingungen) sowie dem generierenden Backend erlaubt eine flexible Anpassung des generierten Codes. Dies zeigt sich insbesondere bei dem darauf basierten Codegenerator zur UML/P [Sch12]. Dabei treten die FreeMarker-Skriptsprache sowie die Zielsprache in gemischter Form auf. Um die Templates und damit die Zielstruktur des Codes nicht übersichtlich zu managen wird eine Strukturierung der Templates entlang der Zielstruktur des Codes und gleichzeitiger Unterstützung durch MontiCore-Basisfunktionen vorgeschlagen. Das in Java realisierte Generator-Framework MontiCore und damit auch der UML/P-Generator [Sch12] kann um eigene Basisfunktionen erweitert werden, im Allgemeinen kommt der Nutzer aber mit der Templatesprache selbst aus.
Ist eine Entscheidung zugunsten einer Skriptsprache und einer Template-Sprache gefallen, so stellt sich die Frage, ob sich die Effekte der Skripte für den Anwender des Generators in kompakter, verständlicher, aber gegebenenfalls informeller Form darstellen lassen, die nicht auf der doch mit vielen Implementierungsdetails behafteten Skriptsprache beruhen. Dieser Wunsch wird noch verständlicher, wenn die XML-basierte sehr verbose Transformationssprache XSLT verwendet werden muss. In diesem Buch soll aber weniger die konkrete Ausformulierung der Codegenerierung, sondern die Konzeption als Transformationen im Vordergrund stehen, weshalb eine abstrakte Darstellung als Transformationen gewählt wird.
4.4.2 Darstellung von Skripttransformationen
Der Effekt eines für die Codegenerierung verwendeten Skripts beruht darauf, UML/P-Konzepte in die Zielprogrammiersprache Java zu transformieren. Da ein solches Skript auch Rand- und Sonderfälle behandelt, Rahmenbedingungen prüft und dazu eine Reihe von Hilfsfunktionen nutzt, ist es zweckmäßig den Effekt eines solchen Skripts in kompakter Form darzustellen, dabei Sonderfälle nur informell zu diskutieren und so für den Anwender verständlich zu machen. Dazu wird die Schablone in Tabelle 4.11 vorgeschlagen, in der neben der eigentlichen Transformation Kontextbedingungen eine allgemeine Beschreibung angegeben und potentielle Alternativen diskutiert werden können. Diese Beschreibung ist weder als vollständig noch als formal anzusehen, obwohl sie einigen nachfolgend beschriebenen Einschränkungen unterliegt. Diese Schablone stellt eher eine abstrakte Illustration für die Beschreibung von Transformationen dar.
|
|
|
|||||
|
Name der Transformation
|
||||||
|
|
|
|||||
|
Erklärung |
||||||
|
|
||||||
|
Transformationsregel |
Meist gibt es eine primäre Transformationsregel, die in folgender Form dargestellt wird:
|
|||||
|
|
|
|||||
|
|
||||||
|
weitere Transformationen |
Aus der Haupttransformation ergeben sich meist zusätzlich notwendige Transformationen, die in analoger Form dargestellt werden. Diese Transformationen beziehen sich zum Beispiel auf Elemente der in Abschnitt 4.2.2 diskutierten API, die ebenfalls zu transformieren sind. |
|||||
|
|
||||||
|
Beachtenswert |
Dieser Abschnitt rundet durch zusätzliche Betrachtungen, Hinweise und die Diskussion potentieller Problemstellungen die Beschreibung ab. |
|||||
|
|
|
|||||
|
Tabelle 4.11.: Name der Transformation
|
||||||
Der verwendete Regelmechanismus ist angelehnt an formale Regelkalküle der Form
| Ursprung | |
| ⇓ | |
|
|
Rahmenbedingungen, |
| Ziel |
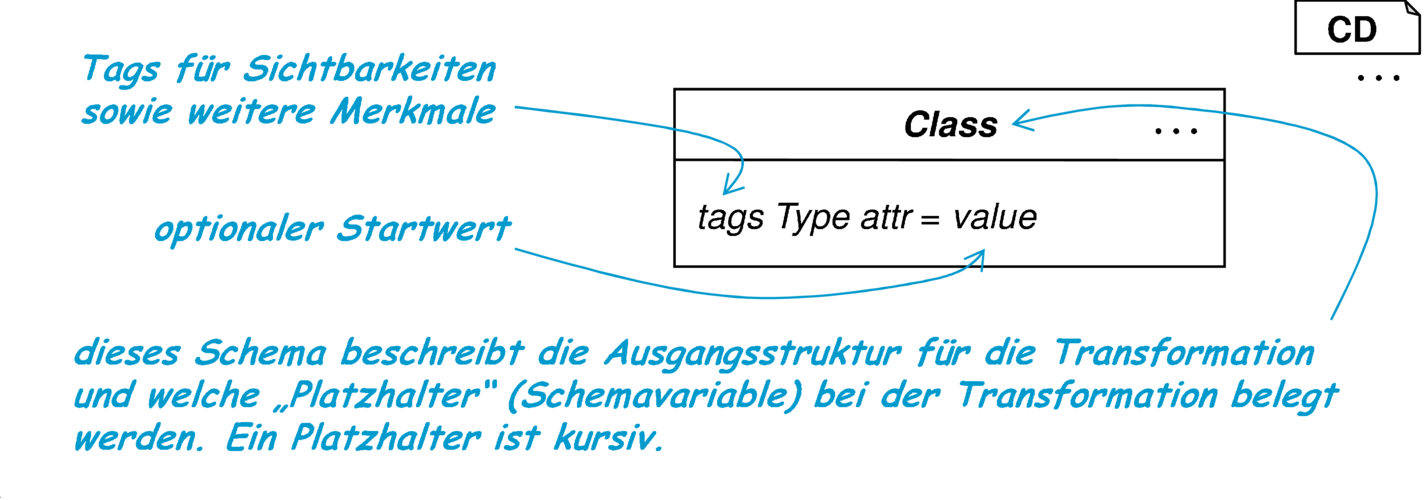
die neben Ursprung und Ziel eine präzise Angabe der Rahmenbedingungen in einer formalen Notation enthalten. Der Ursprung enthält Schemavariablen (Platzhalter, [BBB+85]), die bei der Anwendung der Transformation mit echten Sprachelementen belegt werden. Jede Schemavariable ist einem bestimmten Nichtterminal zugeordnet, ist also damit typisiert.
Nachfolgend ein Anwendungsbeispiel für eine Standardtransformation, die die in Abbildung 4.8 exemplarisch gezeigte Codegenerierung vornimmt.16
Wie bereits in Abschnitt 4.2.2 besprochen, stellt die hier dargestellte Umsetzung nur eine von mehreren Möglichkeiten dar, die zum Beispiel durch die Verwendung geeigneter Stereotypen und Merkmale am Attribut, der Klasse oder dem Klassendiagramm, aber auch durch Angabe bestimmter Skripte ausgewählt werden können.
|
|
|
||||||||||||||
|
Attribut1: Standardtransformation von Attributen
|
|||||||||||||||
|
|
|
||||||||||||||
|
Erklärung |
Die Standardform zur Übersetzung von Attributen mit Kapselung und Zugriff durch explizite Zugriffsfunktionen. Typ- oder projektspezifische Funktionalitäten sind nicht enthalten. |
||||||||||||||
|
|
|||||||||||||||
|
Attributdefinition |
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|||||||||||||||
|
Attributzugriff |
|
||||||||||||||
|
|
|||||||||||||||
|
Attributbesetzung |
|
||||||||||||||
|
|
|||||||||||||||
|
Beachtenswert |
Typspezifische Konstrukte wie attr++ können entweder durch zusätzliche Funktionalität effizient umgesetzt oder in setAttr(getAttr()+1) transformiert werden. Merkmale und Stereotypen werden in dieser Standardumsetzung nicht berücksichtigt. In UML ist es möglich, Attributen eine Kardinalität zuzuordnen. Im Fall „⋆“ ist eine Umsetzung ähnlich der Assoziation vorzunehmen. |
||||||||||||||
|
|
|
||||||||||||||
|
Tabelle 4.12.: Attribut1: Standardtransformation von Attributen
|
|||||||||||||||

Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |