Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
4.1 Konzepte der Codegenerierung
4.2 Techniken der Codegenerierung
4.3 Semantik der Codegenerierung
4.4 Flexible Parametrisierung eines Codegenerators
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
4.2 Techniken der Codegenerierung
4.2.1 Plattformabhängige Codegenerierung
Obwohl mit der Festlegung der UML/P auf die Programmiersprache Java bereits eine wesentliche Entwurfsentscheidung getroffen wurde, ist die Form des generierten Codes nicht eindeutig festgelegt. Es gibt mehrere Dimensionen von Variationen, die bei der Codegenerierung zu beachten sind. Dazu zählt zum einen die hier besprochene Plattformabhängigkeit, die besonders bei eingebetteten Systemen eine wesentliche Rolle spielt.
Je nach Zielplattform stehen unterschiedliche Mechanismen zur Verfügung, um zum Beispiel Kommunikation im verteilten System mit den gesteuerten Anlagen, Nachbarsystemen, der Cloud oder Nutzern sowie Speicherung und Fehlerbehandlung durchzuführen oder die Einbruchssicherheit, Datenauthentizität und -integrität sicher zu stellen.
Diese Mechanismen können abhängig sein von der Hardware, in der die Software eingebettet ist, oder an die zur Verfügung stehenden Klassenbibliotheken beziehungsweise API’s anzupassen sein. Die dabei in generierten Code einzusetzenden Codestücke sind vom Codegenerator nicht vorauszusehen, da beispielsweise durch neue Plattformen, neue Steuergeräte oder neue Versionen von Klassenbibliotheken ein stetiger und schneller Wandel stattfinden kann. Deshalb ist es wesentlich, dass die Codegenerierung flexibel an die jeweiligen Rahmenbedingungen angepasst werden kann. Dazu gibt es zwei wesentliche Ansätze:
Generierung für abstrakte Schnittstellen, wie in Abbildung 4.4 illustriert, und die
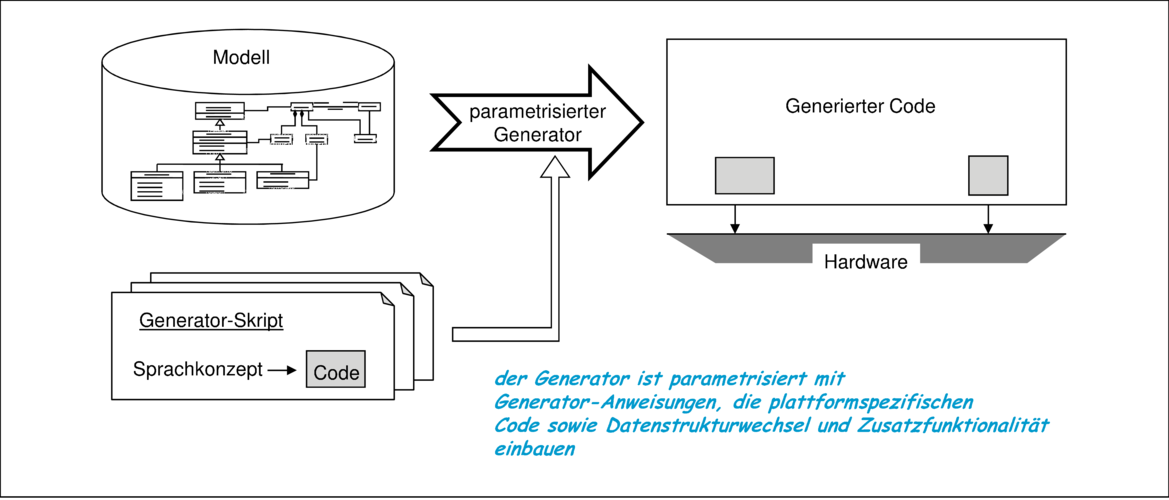
Parametrisierung der Codegenerierung, wie in Abbildung 4.5 gezeigt.
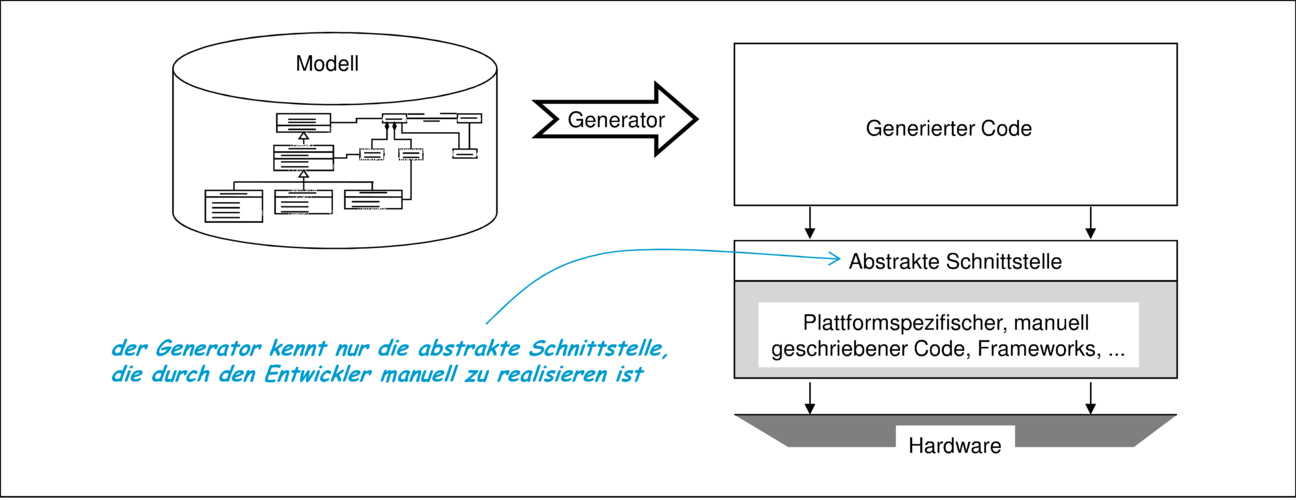
Für die Trennung von plattformspezifischem und hardwareunabhängigem Code ist die Bildung einer abstrakten Schnittstelle und damit die Schichtentrennung ein ideales Werkzeug, das die Portabilität von Software verbessert. Viele der Java-API’s sind genau für diesen Zweck definiert und zum Standard erhoben worden. In [SD00] wurde diese strikte Trennung von Code in Anwendungscode („A-Code“) und plattformspezifischen, technischen Code („T-Code“) detaillierter untersucht sowie notwendige Mischformen identifiziert. Eines der Ergebnisse dieser durch die Praxis untermauerten Untersuchungen ist dabei, dass eine standardisierte „T-Architektur“, also der technische Code für die Speicherung, Anzeige, Fehlerbearbeitung und ähnliche standardisierbare technische Funktionalitäten ein hohes Potential zur Wiederverwendung hat. Dieses Potential kann bei der Codegenerierung durch die flexible Kombination von T-Architektur-Anteilen mit den vom Entwickler vorgegebenen Applikations(A)-Modellen ausgeschöpft werden.
Die strikte Trennung der beiden Codearten kann aber wie immer bei der Einführung von Schichten und Adaptern zu Ineffizienzen führen. Beispielsweise basiert unser Auktionssystem auf asynchroner Kommunikation von Nachrichten. Wenn die abstrakte Schnittstelle aber nur einen RPC-Mechanismus zur Verfügung stellt, so muss unter anderem die Pufferung der Nachrichten selbst codiert werden. Auf unterster Ebene wird aber wieder asynchron über das Internet kommuniziert, wo Puffermechanismen bereits eingebaut sind. Eine Effizienzsteigerung um einen deutlichen Faktor kann zum Beispiel durch Aufgabe der konzeptuell vorhandenen Schichtenbildung und durch ein „Verweben“ höherer und niederer Schichten erreicht werden.11 Alternativ kann die angebotene abstrakte Schnittstelle auch breit angelegt sein und im Beispiel sowohl synchronen RPC als auch asynchrone Kommunikation anbieten. Das führt aber zu erheblichem Mehraufwand bei der Realisierung und Weiterentwicklung und zahlt sich nur aus, wenn ausreichend oft eine Wiederverwendung in anderen Projekten stattfindet.
Wird darüber hinaus angenommen, dass die Generierung des Zielcodes korrekt ist und auf eine manuelle Nachbearbeitung oder Inspektion verzichtet, so ist die Einhaltung architektureller Guidlines wie etwa die Schichtenbildung im generierten Code nicht sehr relevant. Stattdessen kann bei der Generierung mehr auf Effizienz geachtet werden und ähnlich zu Optimierungstechniken der Compiler ein Verweben des plattformunabhängigen und -spezifischen Codes erfolgen. Dadurch entsteht nach [SD00] ein sehr schwer wartbarer AT-Code, der sowohl Anwendungs- als auch technisches Wissen beinhaltet. Auch deshalb ist es wesentlich, dass der generierte Code nicht manuell weiterbearbeitet wird, sondern nur die nach A- und T-Gesichtspunkten getrennten Ausgangsmodelle und die Generatorskripte.
In der Praxis ist davon auszugehen, dass eine Mischform aus beiden Generierungsmechanismen zu den besten Ergebnissen führen wird. Darüber hinaus wird ein System eine weitere Komponente besitzen, die eine Laufzeitumgebung für bestimmte Funktionalitäten zur Verfügung stellt, die weder in Java-Klassenbibliotheken noch in Java-Sprachkonzepte abgebildet werden können. Dazu gehören zum Beispiel erweiterte Funktionalitäten zur Behandlung der in OCL verfügbaren Mengen und Listen ebenso wie die Bearbeitung von explizit im Code abgelegten Zustandsmodellen. Abbildung 4.6 beschreibt daher die prinzipielle Struktur eines Codegenerators.
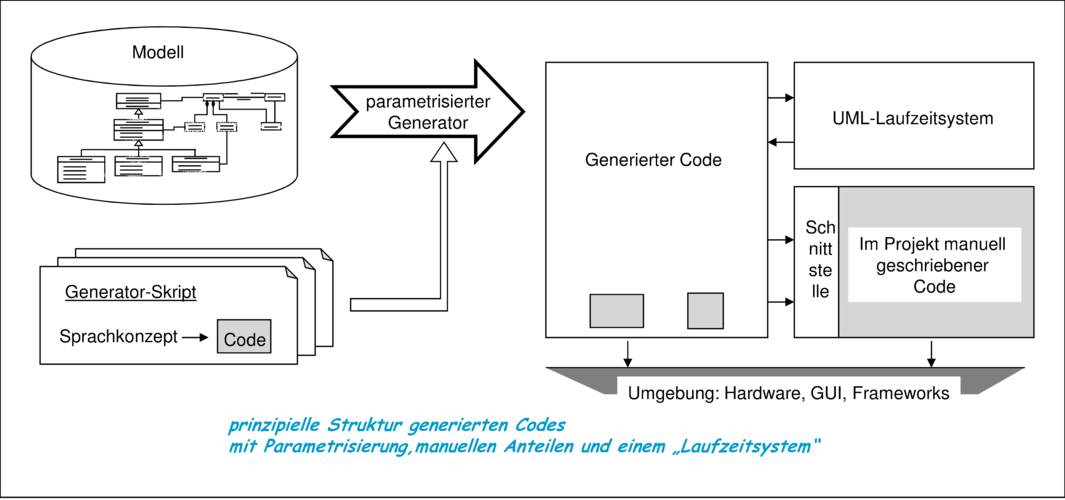
Der unter anderem in [BBWL01, RFBLO01] geprägte Begriff der „UML Virtual Machine“ entspricht dabei dem rechten Teil des Bildes 4.6, bestehend aus dem UML-Laufzeitsystem und einer plattformspezifischen Implementierung der festgelegten Schnittstellen. Angelehnt an die “Java Virtual Machine“, dem Interpreter des Java-Bytecodes, entspricht der Codegenerator dem Java-Compiler. Die “UML Virtual Machine“ stellt eine Art operationeller Semantik des ausführbaren Teils der UML/P dar.
4.2.2 Funktionalität und Flexibilität
Die im letzten Abschnitt angesprochene Parametrisierung der Codegenerierung kann nicht nur zur Anpassung an plattformspezifische Merkmale verwendet werden, sondern auch dafür, den erzeugten Code um zusätzliche Funktionalität zu erweitern. Im Prinzip sind der dabei entstehenden Flexibilität kaum Grenzen gesetzt. Nachfolgend wird dies an dem einfachen und weitgehend bekannten Beispiel der Codegenerierung für Attribute im Klassendiagramm diskutiert.
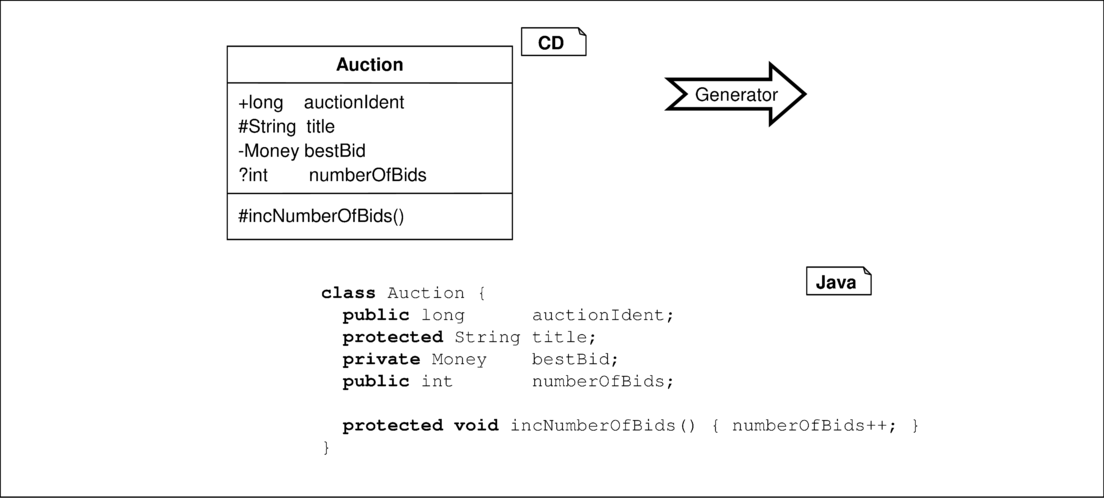
Ein in einer Klasse des Klassendiagramms definiertes Attribut besitzt die in Abbildung 4.7 demonstrierte „natürliche“ Umsetzung als Attribut im generierten Java-Code. Mit Ausnahme der Merkmale für abgeleitete und für nur lesbare Attribute (/ und readonly) können alle Merkmale, Typen und initialen Zuweisungen an das Attribut direkt umgesetzt werden. Diese direkte Umsetzung birgt jedoch einige Nachteile, wie zum Beispiel den nicht gekapselten und nicht synchronisierten Zugriff durch andere Objekte.
Deshalb ist es heute nicht üblich, Attribute aus Analyse- und Entwurfsmodellen direkt in Attribute der Implementierung umzusetzen, sondern stattdessen eine Infrastruktur in Form von so genannten get- und set-Methoden zur Verfügung zu stellen. Abbildung 4.8 zeigt die so entstehende Codestruktur. Dabei wird oft jedem Attributnamen ein geeigneter Präfix (hier zum Beispiel der Unterstrich „_“) vorangestellt. Die Verwendung von Zugriffsfunktionen erhöht die Flexibilität. Sie erlaubt zum Beispiel die möglicherweise notwendige Synchronisation von Threads oder die Realisierung des Zugriffsrechts readonly durch zwei get/set-Methoden mit unterschiedlichen Sichtbarkeitsangaben.
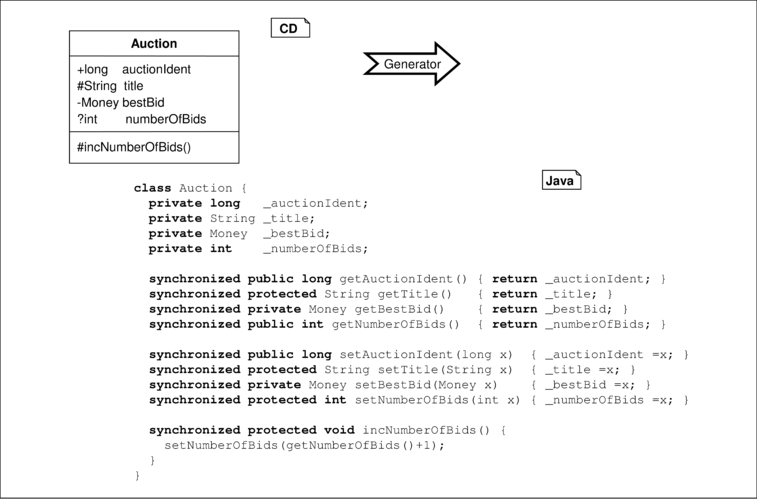
Die in den beiden Abbildungen 4.7 und 4.8 skizzierten Umsetzungen sind heute relativ verbreitet, aber keineswegs die einzigen. Es gibt weitere Varianten, die zum Beispiel persistente Attribute, eine Ablage der Attribute in Enterprise JavaBeans [BR11], Propagierung von Attributänderungen und dergleichen mehr erlauben. Um die verschiedenen und auch nicht generell vorhersehbaren Varianten der Codegenerierung dennoch flexibel zu ermöglichen, ist es grundsätzlich notwendig, die Umsetzung von Konzepten der UML/P stark zu parametrisieren und technologiespezifisch ergänzbar zu halten.
In gewisser Weise sind für die Konzepte der UML/P „API’s“12 identifizierbar, die jeweils umzusetzen sind. Für das Konzept „Attribut“ der Klassendiagramme lässt sich beispielsweise mindestens folgendes API identifizieren:
- Setzen eines Attributs,
- Auslesen eines Attributs und
- Initialisierung eines Attributs mit einem Defaultwert.
Erweiterungen dieses API’s können zum Beispiel für
- Serialisierung,
- Laden aus und Speichern in einer Datenbank,
- Bildschirmausgabe und Einlesen aus einer Bildschirmmaske
oder für typspezifische Funktionalitäten definiert werden. Dazu gehören zum Beispiel die Inkrementierung von Zahlenwerten, das Anhängen von Strings (analog dem Java-Operator +=) oder die Behandlung einzelner Elemente in Containerstrukturen.
Die für eine Codegenerierung wünschenswerte Flexibilität besteht also nicht nur in der Form der Umsetzung von UML/P-Konzepten, sondern auch in der damit angebotenen Funktionalität. Die angebotene Funktionalität muss nicht nur generiert werden, sondern auch in einer Form zur Verfügung stehen, die es dem Entwickler erlaubt, an anderer Stelle darauf zuzugreifen. Dabei gibt es zwei generelle Verfahren:
- Die Umsetzung des API’s wird offen gelegt, indem zum Beispiel aus dem Namen und dem Typ eines Attributs eindeutig die Namen und Signaturen der jeweils
verwendbaren Funktionen abgeleitet werden können.
Ist also beispielsweise das Attribut title im Klassendiagramm definiert, so kann in Java mit getTitle() und setTitle(...) darauf zugegriffen werden.
- Es wird das API selbst offengelegt, die Umsetzung aber bleibt verborgen. Der manuell geschriebene Java-Code nutzt daher direkt das API und muss bei der
Codegenerierung ebenfalls transformiert werden.
Im Beispiel wird dann auch im Java-Code das Attribut title benutzt. Dies wird je nach Anwendungsform (lesend oder schreibend) bei der Codegenerierung durch eine get- oder set-Methode ersetzt.
Während der erste Ansatz zu einfacheren Codegeneratoren führt und keine Behandlung des Java-Codes erfordert, ist beim zweiten Ansatz mehr Flexibilität und Codierungssicherheit gegeben. Durch das Verbergen der tatsächlichen Implementierung kann diese relativ einfach ersetzt oder ergänzt werden. Außerdem ist die Verwendung der API abstrakter und führt zu kompakterem Code. Jedoch wird es in diesem Ansatz notwendig, bei der Codegenerierung auch direkt in Java formulierte Codeteile zu transformieren.
Wie das relativ einfache Beispiel zur Realisierung von Attributen zeigt, lassen sich bereits daran viele der auftretenden Effekte studieren. Deshalb wird im folgenden Abschnitt 4.4 zunächst eine lesbare Form der Darstellung von Codegenerierungen beschrieben und deren Einsatzfähigkeit anhand der Transformation von Attributen demonstriert.
Die bei der Umsetzung von UML/P-Konzepten in die Implementierung zur Verfügung stehenden Formen der Codegenerierung haben unter Umständen Auswirkungen auf die Semantik der Konzepte. Dies ist nicht unkritisch, aber auch eine Chance für Anwender der UML, die semantischen Freiheitsgrade, oft auch als „variation points“ bezeichnet, zu nutzen, um projektspezifische oder zusätzliche Funktionalitäten und Fähigkeiten zu integrieren. Diese Freiheitsgrade präzise zu beschreiben ist innerhalb der UML nicht möglich, einerseits weil die UML selbst keine Mechanismen für ihre Semantikdefinition zur Verfügung stellt, andererseits weil diese Freiheitsgrade keine allgemeine Gültigkeit besitzen, sondern abhängig von potentiellen Zielplattformen und gewünschten Funktionalitäten sind.13 Es bleibt daher in der Praxis oft nur die Möglichkeit, jeweils einzelne Formen der Codegenerierung und die damit intendierte semantische Interpretation in konstruktiver Form anzugeben. Eine umfassende Beschreibung der Menge möglicher Varianten in ihrer gesamten Bandbreite erscheint nicht möglich. In [Grö10] wurden Feature-Diagramme eingesetzt, um Variationspunkte in Sprachen zu definieren und zum Beispiel in [GRR10, GR10] an mehreren Diagrammen angewendet.
Die Trennung der Funktionalität und der plattformabhängigen Codeteile wurden im Bereich des Aspect-Oriented-Programming (AOP) [KLM+97, LOO01] beziehungsweise der damit eng verwandten generativen Programmierung [CE00] bereits eingehend diskutiert. Dabei werden Techniken vorgestellt, die eine noch weitergehende Trennung einzelner Programmaspekte erlauben. Spezielle Verfahren (so genanntes „Weaving“) erlauben die Kombination zunächst unabhängig voneinander formulierter und meist nur über eine abstrakte Programmierschnittstelle verbundener Codeteile. Diese Vorgehensweise wird in eingeschränkter Form auch bei der hier diskutierten Codegenerierung verwendet.
Auch die in [Pre97, Pre00, KPR97] diskutierte Komposition von Klassen aus Features und deren Interaktionen kann durch einen generativen Ansatz realisiert werden. Welche Klasse bei der Generierung welche (zusätzlichen) Features erhält, kann durch Stereotypen und Merkmale in geeigneter Form gesteuert werden.
4.2.3 Steuerung der Codegenerierung
Um die bereits mehrfach erwähnte, notwendige Flexibilität in der Codegenerierung in der vollen Bandbreite zu nutzen, muss die Übersetzung sinnvoll gesteuert werden können. So ist es oft sinnvoll, verschiedene Ausprägungen desselben Konzepts innerhalb eines Projekts, unterschiedlich zu realisieren. Die bereits mehrfach diskutierten Möglichkeiten zur Umsetzung von Attributen können zum Beispiel abhängig sein von
- der Klasse, die das Attribut beinhaltet, weil diese Klasse Aufgaben wie Datenhaltung oder Applikationssteuerung haben kann oder als Schnittstelle zu anderen Systemteilen wirkt und daher zu synchronisieren ist,
- der Aufgabe des Attributs innerhalb der Klasse, weil beispielsweise die Klasse persistent ist, das Attribut aber berechnet werden kann oder nur temporäre Daten beinhaltet oder
- dem Typ des Attributs, weil dieser beispielsweise in UML/P, nicht aber in Java existiert.
Diese statisch, also zur Zeit der Codegenerierung festgelegten Abhängigkeiten können durch dynamische Abhängigkeiten ergänzt werden, wenn zum Beispiel ein Flag benutzt wird, um festzulegen, ob ein Objekt persistent sein soll. Projektspezifische Fälle wie diese sollten typischerweise nicht mehr durch eine vorgegebene Semantikdefinition, sondern durch selbstdefinierten Code realisiert werden, der durch den mit Templates parametrisierten Codegenerator systematisch hinzugefügt wird.
Die Steuerung der Implementierungsform jedes UML/P-Konzepts kann grundsätzlich durch Stereotypen und Merkmale erfolgen. Jedoch ist die ausschließliche Verwendung von Stereotypen und Merkmalen in der Praxis nicht ausreichend. Stattdessen reduziert sich die Markierung der UML-Diagramme im Wesentlichen auf den Stereotyp-Namen, optional ergänzt um zusätzliche Parameterwerte. Die Umsetzung eines mit einem Stereotyp markierten UML/P-Elements in eine Implementierung wird durch zusätzliche Templates oder Skripte vorgenommen, die durch den Codegenerator ausgeführt werden und diesen, wie in Abbildung 4.6 skizziert, sehr flexibel parametrisieren.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |