Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
4.1 Konzepte der Codegenerierung
4.2 Techniken der Codegenerierung
4.3 Semantik der Codegenerierung
4.4 Flexible Parametrisierung eines Codegenerators
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
4.3 Semantik der Codegenerierung
Eine Codegenerierung ist im Prinzip eine Transformation eines Modells einer Sprache in eine andere Sprache. Auch eine Semantikdefinition ist im Wesentlichen eine Abbildung einer als unbekannt betrachteten Sprache (hier also UML/P) in eine als bekannt und als verstanden angesehene Zielsprache. Ist die Zielsprache darüber hinaus formal und die Abbildung präzise formuliert, so wird auch von einer formalen Semantik gesprochen. In diesem Sinn kann eine durch ein Programm implementierte Abbildung der UML/P in die Programmiersprache Java selbst als eine formale Semantik verstanden werden [HR04]. Dabei gibt es allerdings mehrere Punkte, die bei dieser Argumentation zu beachten sind:
- Es ist für das Verständnis einer Sprache wie UML/P hilfreich, mehr als nur eine Bedeutungserklärung (Semantik) zur Verfügung zu haben. Durch Verwendung mehrerer Herangehensweisen zur Definition einer Semantik einer Sprache werden unterschiedliche Probleme erkannt und können so in die Sprachdefinition und deren Benutzung (Analyse, Tests, Refactoring) zurückfließen.
- Der generierte Code ist typischerweise nicht unbedingt gut lesbar, denn er enthält im Allgemeinen eine Vielzahl von technologie- oder frameworkspezifischen Details, die zudem nicht zur eigentlichen Semantik des Modells beitragen. Es ist daher nicht allgemein zumutbar, zum Verständnis der Bedeutung einer Modellierungssprache den generierten Code inspizieren zu müssen. Allerdings gibt es eine Reihe von Sprachbeschreibungen, die darauf beruhen, das Prinzip der Codegenerierung allgemein zu diskutieren. Sie sprechen damit ein breites Publikum an, da heute Programmiersprachen wie Java die am verbreitetsten „formalen Sprachen“ sind.
- Bestimmte Aspekte einer Sprache können bei der Umsetzung in ablauffähigen Code nicht oder nur mit großem Aufwand umgesetzt werden. Dazu gehören zum Beispiel Konzepte, die Unterspezifikation erlauben und die in der UML/P an mehreren Stellen eingebaut sind. So können initialisierende Werte für Attribute fehlen oder im Statechart mehrere alternative Transitionen gleichzeitig schaltbereit sein. Der dabei entstehende Nichtdeterminismus wird bei einer Codegenerierung im Normalfall durch die Auswahl einer höher priorisierten Transition aufgelöst (siehe Abschnitt 5.4.4, Band 1). Das durch den generierten Code beschriebene System ist daher im Allgemeinen nicht identisch zum Ausgangsmodell, sondern stellt eine von mehreren möglichen Spezialisierungen dar. Weil eine Programmiersprache per se ausführbar ist, ist die Abbildung von Unterspezifikation und damit eine vollständige Semantikdefinition der UML/P zum Beispiel nach Java prinzipiell nicht möglich.
- Die UML/P ist teilweise auf Ausführbarkeit ausgelegt, erlaubt jedoch an vielen Stellen die Verwendung von nicht ausführbaren Konzepten. Dazu gehören neben den bereits erwähnten Möglichkeiten, Modellinformationen wegzulassen, unter anderem die Spezifikation von Bedingungen mit unendlichen Quantoren. Auch die nachfolgend noch genauer diskutierte Frage der Umsetzung von OCL-Nachbedingungen gehört zu diesem Problemkreis. Daher ist eine vollständige Abbildung von UML/P nach Java nicht möglich.
Als Alternative zu diesen sehr impliziten Semantikdefinitionen lassen sich Techniken der formalen Methoden einsetzen, um eine formale Semantik für die Quellsprache, unabhängig von irgend einer Form der Codegenerierung, zu definieren. Typischerweise sind solche Semantikdefinitionen Abbildungen die eine UML-Variante in eine geeignete Zielsprache transformieren. Als Zielsprachen werden dabei mathematisch formale Kalküle verwendet und die Abbildungen in kompakter Form definiert, so dass sie einer Analyse leichter zugänglich werden.14 Wie in [HR00] und [Rum98] argumentiert, kann die Existenz zweier Abbildungen für eine Quellsprache verwendet werden, um das Zutrauen in die Korrektheit beider Abbildungen und damit insbesondere in die Codegenerierung zu erhöhen.
Ist die Codegenerierung in der hier vorgeschlagenen Form parametrisiert und haben die benutzten Skripte Einfluss auf Verhalten und Struktur des generierten Codes, so kann dies auf zwei Arten in eine formale Semantikdefinition einbezogen werden. Abbildung 4.9 formalisiert eine Variante zur Semantikdefinition, in der die Semantikabbildung unabhängig vom benutzten Skript ist.
- die Quellsprache (UML/P) als eine Menge UML von syntaktisch wohlgeformten Ausdrücken,
- eine geeignete formale Zielsprache mit dem Sprachschatz Z,
- die Skriptsprache des Codegenerators mit dem Sprachschatz S und
- die Menge J aller Java-Programme.
Ein Codegenerator ist eine unter Umständen partielle Abbildung Gen : UML → J.
Eine formale Semantik ist demgegenüber eine Abbildung Sem : UML → ℙ(Z). Damit wird einem einzelnen typischerweise unterspezifizierten und abstrakten Modell aus der Quellsprache eine Menge von möglichen Implementierungen zugewiesen, die mit eben diesem Modell gemeint sind. Dies stellt eine Form der losen Semantik dar.
Für einen Vergleich beider Abbildungen Sem und Gen ist eine Semantik für Java-Programme in der Form SemJava: J → Z notwendig. Dann muss für jedes UML-Dokument u ∈ UML, für das Code generiert werden kann, gelten:
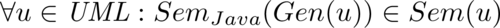
Das heißt, im Allgemeinen wählt der Codegenerator eine von mehreren möglichen Implementierungen aus, indem er etwa offene Aspekte durch Defaults ausfüllt. Nur wenn Sem(u) ein einziges Element darstellt, war die Spezifikation offensichtlich vollständig und eindeutig.
Ein parametrisierter Codegenerator wird um die Parameter, also die Skriptsprache S, erweitert: Genp : UML × S → J. Es muss nun gelten:
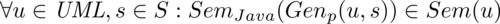
Das heißt, im Rahmen der Vorgabe durch Sem(u) darf das Skript s eine mögliche Implementierung für u auswählen.
Die in Abbildung 4.9 dargestellte Formalisierung nutzt die mengenwertige Semantikabbildung zum Beispiel auf ein Systemmodell [BCGR09b], um damit die Variabilität des parametrisierten Codegenerators darzustellen. Die Formalisierung hängt sehr stark von den dadurch beobachteten Aspekten einer Sprache ab. Wird zum Beispiel nur das extern sichtbare Verhalten formalisiert, so sind in Bezug auf Umsetzung von Attributen, Assoziationen und anderen Strukturelementen Freiheiten gegeben. Tatsächlich ist es für eine so umfangreiche Sprache wie die UML kaum praktikabel, eine vollständige Formalisierung vorzunehmen, obwohl dies in [Öve00] bemerkenswert vollständig, aber nicht sehr elegant gelungen ist. Stattdessen ist es sinnvoll, einzelne, kritische Aspekte genauer zu beleuchten und damit Rückkopplung in den Standardisierungsprozess zu geben. In einer Reihe von Publikationen wurden auch die prinzipiellen Vorteile und Probleme einer Standardisierung diskutiert [BHH+97, FELR98b, FELR98a].
Eine alternative Sichtweise zu der in Abbildung 4.9 dargestellten Form ist die Einbeziehung der Skriptsprache S in die Semantikdefinition. Quellsprache und Skriptsprache stellen dann in gewisser Weise die gemeinsame „Programmiersprache“ dar. Eine Semantikdefinition kann dies in Form einer Funktion Semp : UML × S → Z widerspiegeln, die die Auswahl genau eines Elements der Zielsprache Z vornimmt.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |