Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
8.1 Dummies
8.2 Testbare Programme gestalten
8.3 Behandlung der Zeit
8.4 Nebenläufigkeit mit Threads
8.5 Verteilung und Kommunikation
8.6 Zusammenfassung
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
8.5 Verteilung und Kommunikation
Echt verteilte Programme unterscheiden sich von rein nebenläufigen Programmen durch die räumliche oder konzeptionelle Verteilung der Teilsysteme. Daraus resultieren getrennte Speicher, die ein gemeinsames Arbeiten auf denselben Objekten verhindern und explizite Kommunikation notwendig machen [Bro98, Bog99].
Systeme wie das Auktionssystem, die im Internet verteilt sind, können auf verschiedene Arten kommunizieren. Mehrere Frameworks und Technologien, wie RMI oder CORBA, bieten unterschiedlich gute Unterstützung und erlauben teilweise sogar die an sich asynchrone Kommunikation übers Internet durch einen simuliert synchronen Methodenaufruf zu ersetzen.
8.5.1 Simulation der Verteilung
Verteilte Systeme sind ebenfalls nebenläufige Systeme und daher inhärent nichtdeterministisch. Dazu kommt, dass anders als bei normaler Thread-Programmierung ein Ausfall eines Kommunikationspartners relativ häufig vorkommt, weil zum Beispiel die Internet-Leitung unterbrochen, der Rechner ausgeschaltet oder das Client-Applet terminiert wurde. Zustandsbasierte Kommunikation, bei der also auf wenigstens einer Seite der Zustand des Kommunikationspartners gespeichert wird, muss daher spontane Zustandsübergänge des Partners in Tests miteinbeziehen.
Das für Tests verteilter Systeme allgemein verwendbare Prinzip ist auf dem Scheduling nebenläufiger Threads aufgebaut. Das Muster für die Simulation der Nebenläufigkeit aus Tabelle 8.22 ist daher grundsätzlich auch für die Simulation verteilter Systeme geeignet. Es müssen jedoch einige zusätzliche Probleme beachtet werden.
So können Threads, die für unterschiedliche Prozessräume konzipiert sind, im Test innerhalb eines Prozessraums auf ungewollte Weise interagieren. So teilen sich im Testablauf alle Threads dieselben statischen Variablen. Dies kann dadurch umgangen werden, dass bei jedem Wechsel des Threadkontexts die statischen Variablen geeignet umgesetzt werden oder in einer redefinierbaren Schnittstelle gekapselt sind. Dazu eignet sich in hervorragender Weise das Singleton-Muster aus Tabelle 8.9, bei der die Realisierung der do…-Methode durch Festlegung des jeweils aktiven Kontexts das jeweils richtige Objekt verwendet. Dieses Konzept ist ähnlich zu der Verwendung der Session-Objekte in JSP [FK00], die den Kontext des gerade aktiven Threads definieren. Jedoch ist in dem hier vorgestellten Ansatz durch die zusätzliche Kapselung in einer statischen Methode die Verwendung für den Nutzer nicht sichtbar.
Abbildung 8.23 zeigt einen einfachen Scheduler, der eine Nachricht am Server ablegt und dann zwei Clients zum Abholen der Nachricht veranlasst.
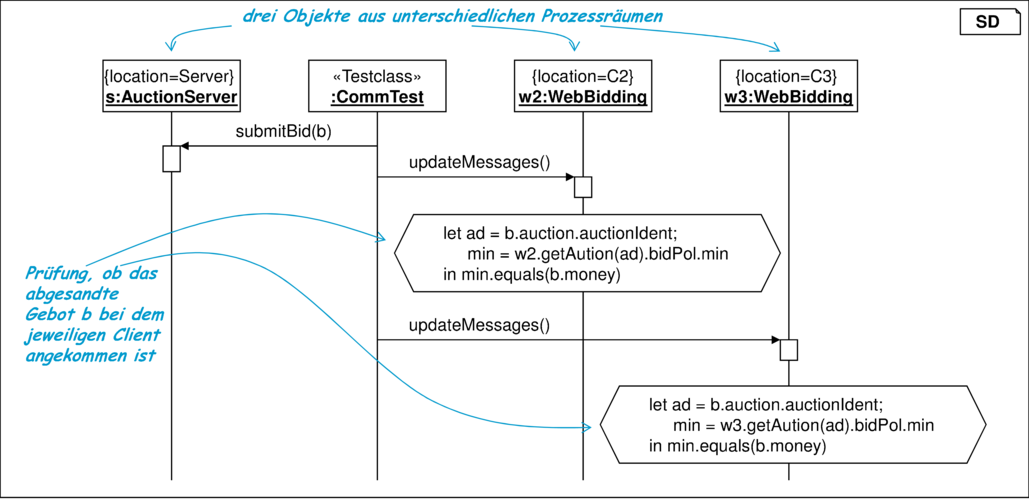
Die eigentliche Kommunikation ist in diesem Sequenzdiagramm nicht enthalten. Sie wird erst nachfolgend behandelt. Die am Test beteiligten Objekte sind mit dem in Tabelle 8.24 eingeführten Merkmal {location} parametrisiert, dessen Wert den jeweiligen Prozessraum beschreibt. Vor der Ausführung des jeweiligen Methodenaufrufs wird der Prozesskontext umgestellt, so dass jede angestoßene Tätigkeit ihre natürliche Umgebung vorfindet.
|
|
|
|
Merkmal {location}
|
|
|
|
|
|
Modellelement |
Objekte im Objektdiagramm und im Sequenzdiagramm.
|
|
|
|
|
Motivation |
Beschreibt die physische oder konzeptionelle Verteilung der damit markierten Objekte in verschiedenen Prozessräumen. |
|
|
|
|
Glossar |
Die mit dem Merkmal beschriebene Ortsangabe heißt Lokation6. |
|
|
|
|
Rahmenbedingung |
Da Prozessräume physisch oder konzeptionell verteilt sind, sind normalerweise Links und Aufrufe zwischen Objekten verschiedener Prozessräume nicht möglich. Eine Ausnahme wird dafür allerdings für Testtreiber und Kommunikationselemente gemacht. |
|
|
Objekte, die aufgrund eines Sequenzdiagramms erzeugt werden, gehören zum gleichen Prozessraum, wie das erzeugende Objekt. |
|
|
|
|
Wirkung |
Die physische Verteilung kann in einem Testfall simuliert werden. Jeder Lokation steht eine eigene Umgebung zur Verfügung, die zum Beispiel verhindert, dass die Nutzung statischer Variablen zu unerwünschten Interaktionen führt. |
|
|
Das Merkmal {location} hat als Argument einen Identifikator vom Typ String, der den Namen des Prozessraums darstellt. |
|
|
|
|
Beispiel(e) |
Das Sequenzdiagramm in Abbildung 8.23 nutzt diese Merkmale. |
|
|
|
|
Tabelle 8.24: Merkmal {location}
|
|

Die hier verwendete Umsetzung von Ortsangaben ist eine sehr pragmatische Form der Verwendung von Lokationen zur Modellierung von Systemen. Auch im Ambient-Calculus [CG98] werden Lokationen eingesetzt, um damit dynamische Systeme zu modellieren. Im UML-Standard können in ähnlicher Form auch die in diesem Buch nicht weiter vertieften Deployment-Diagramme verwendet werden.
8.5.2 Simulation von Singletons
Die Simulation eines verteilten Echtzeitsystems erfordert meist die Verwendung unterschiedlicher Systemzeiten für jede einzelne Lokation. Dafür kann das Muster in Tabelle 8.17 zur Zeitsimulation genauso ausgebaut werden, wie auch andere Singletons. Das Muster in Tabelle 8.25 beschreibt, wie ein Singleton pro Lokation verwaltet werden kann.
|
|
|
|||||||||||||||||||||||||||||||
|
Muster: Individuelles Singleton für jede Lokation
|
||||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||
|
Intention |
Wird im Testsystem Verteilung simuliert, so wird mit diesem Muster ermöglicht, jeder Lokation ein eigenständiges Singleton zuzuweisen. Das Muster baut auf dem Singleton-Muster aus Tabelle 8.9 auf. |
|||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||
|
Anwendung |
Durch die Anwendung dieses Musters bleibt dem Produktionscode verborgen, dass eine Verteilung nur simuliert ist. Virtuell hat jede Lokation eigene statische Variablen. |
|||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||
|
Implementierung Singleton |
|
|||||||||||||||||||||||||||||||
|
|
Für die Simulation wird lediglich die Klasse Singleton angepasst. Die Unterklassen der Form SingletonDummy werden genauso definiert, wie in Tabelle 8.9 beschrieben. |
|||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||
|
Beachtenswert |
|
|||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||
|
Tabelle 8.25 : Muster: Individuelles Singleton für jede Lokation
|
||||||||||||||||||||||||||||||||
8.5.3 OCL-Bedingungen über mehrere Lokationen
Durch die im Test verwendete Zusammenlegung mehrerer virtueller Prozessräume gilt die Einzigartigkeit des Singletons nur noch bezüglich seiner Lokation. Dadurch ist für Auktionen über mehrere Lokationen die Eindeutigkeit des Auktionsidentifikators auctionIdent nicht gegeben. Deshalb sind bei simulierter Verteilung OCL-Invarianten entsprechend anders zu interpretieren als einführend in Kapitel 3, Band 1 beschrieben. Grundsätzlich gelten Aussagen wie
OCL  context AllData ad inv AllDataIsSingleton: context AllData ad inv AllDataIsSingleton: |
| AllData == {ad} |
oder
OCL  context Auction a, Auction b inv AuctionIdentIsUnique: context Auction a, Auction b inv AuctionIdentIsUnique: |
| a.auctionIdent == b.auctionIdent implies a == b |
für jede Lokation, nicht jedoch für den gesamten Testfall, da sie implizit Quantoren über der Menge aller vorhandenen Objekte nutzen7
. Deshalb sind die in diesen Testfällen verwendeten OCL-Bedingungen lokal über der Extension einer Klasse zu interpretieren. Dies erfordert zum einen für die durch die Codegenerierung erzeugte Verwaltung der Extension einer Klasse eine zusätzliche Differenzierung nach den Lokationen, denen diese Objekte zugeordnet werden.Zum anderen aber ist es, wie die OCL-Bedingungen in Abbildung 8.23 zeigen, von Interesse, bei der Simulation verteilter Prozesse Bedingungen auszuwerten, die über Prozessgrenzen hinweg formuliert sind. Damit können globale Eigenschaften formuliert werden, wie etwa, dass nach dem Holen der am Server anliegenden Nachrichten der Wert des letzten Gebots b als niedrigstes Gebot beim Client vorliegt. Die dabei verglichenen Money-Objekte gehören zu unterschiedlichen Lokationen.
Für den Fall, dass es nicht wie im Beispiel offensichtlich ist, dass eine OCL-Bedingung global zu interpretieren ist, wird die Verwendung eines Merkmals der Form {global} für OCL-Invarianten vorgeschlagen. Analog kann die Gültigkeit einer OCL-Invariante auf jede der Lokationen einzeln mit {local} und eine bestimmte Lokation eingeschränkt werden, indem diese explizit angegeben wird:
OCL  {location=server} {location=server} |
| context Auction a, Auction b inv AuctionIdentIsUnique: |
| a.auctionIdent == b.auctionIdent implies a == b |
8.5.4 Kommunikation simuliert verteilte Prozesse
Für das Produktionssystem stehen verteilten Prozessen mehrere Kommunikationsmechanismen zur Verfügung. In einem Testlauf mit simulierter Verteilung ist eine echte Kommunikation über ein Netz nicht notwendig. Die zur Kommunikation verwendeten Objekte sind daher durch Dummies zu ersetzen, die die zu übermittelnde Information auf andere Weise übertragen.
Im Auktionssystem ist die Kommunikation durch mehrere selbst entworfene Layer auf Basis direkter HTTP-Anfragen realisiert. Dadurch ist ein sehr effizientes und konfigurierbares System entstanden, das Verschlüsselung, Verwaltung von Kommunikationszuständen in „Sessions“ einfach ein- und ausschalten sowie mit Firewalls und Cache-Systemen verschiedener Arten umgehen kann. Die Grundstruktur der Kommunikation ist unter Abstraktion von Details wie Sessions und Verschlüsselung in Abbildung 8.26 dargestellt und beschreibt nur den Anteil, der für die Gebotsabgabe genutzt wird.
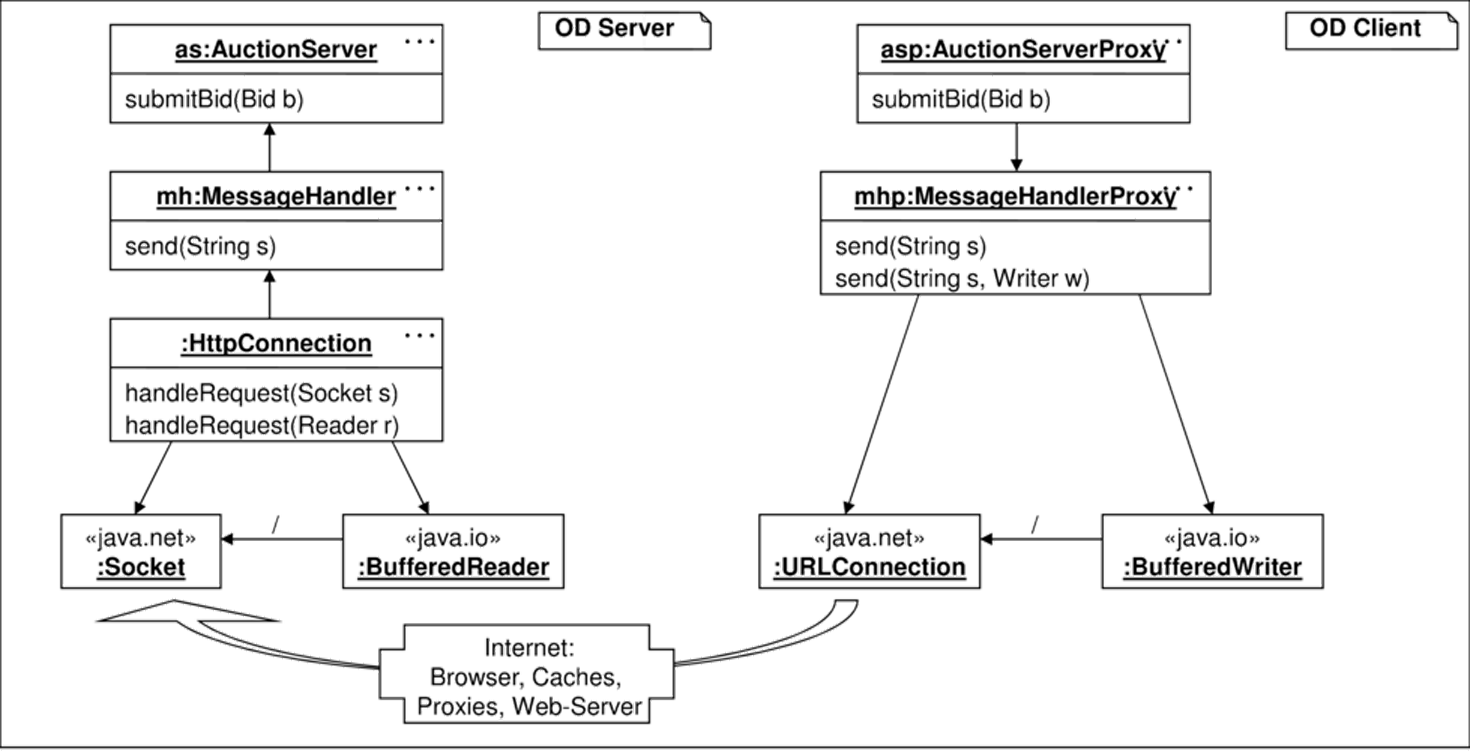
Beim Client entspricht die Aufrufhierarchie der Schichtung, also asp ruft mhp auf, der eine vorhandene Verbindung verwendet oder eine neue erstellt, die Daten in einen verschlüsselten String transformiert und überträgt. Beim Server geht die Aktivität von einer nicht dargestellten Menge vorhandener Threads aus, die am Socket prüfen, ob eine Anfrage vorliegt und diese dann in jeweils eigenen Instanzen der Klasse HttpConnection bearbeiten lassen. Daher geht beim Server die Aktivität von der Klasse HttpConnection aus.
Wie in Abschnitt 8.1 besprochen, lassen sich auch in verteilten Systemen jeweils einzelne oder Kombinationen von Schichten testen. Dazu ist jeweils eine geeignete Konfiguration unter Nutzung von Dummies und Factories zu entwerfen. Die Konfiguration simulierter verteilter Systeme lässt sich durch ein Objektdiagramm darstellen. Beispielsweise ist eine sehr einfache Konfiguration, die jegliche Kommunikationsaspekte ausblendet, durch das Objektdiagramm in Abbildung 8.27 erreichbar. Dabei wird ein Dummy zur Delegation eingesetzt, damit eine Kopie der übertragenen Objekte angelegt werden kann und keine gemeinsamen Objekte in verschiedenen Lokationen genutzt werden.

Durch die Konfiguration in Abbildung 8.28 lässt sich zusätzlich die korrekte Umwandlung der übertragenen Gebote in Strings („Marshalling“) prüfen. Die Schichten wurden jeweils so konstruiert, dass das Original anstelle des Proxy eingesetzt werden kann. In der gezeigten Konfiguration kann sogar auf die Bildung von Kopien bei der Übergabe zwischen den Lokationen verzichtet werden, da Strings unveränderbare Objekte sind.

Weitere Konfigurationen sind möglich, indem etwa die Socket- und URLConnection-Objekte durch Dummies oder wie in Abbildung 8.29 Reader und Writer durch eine Pipe ersetzt werden.
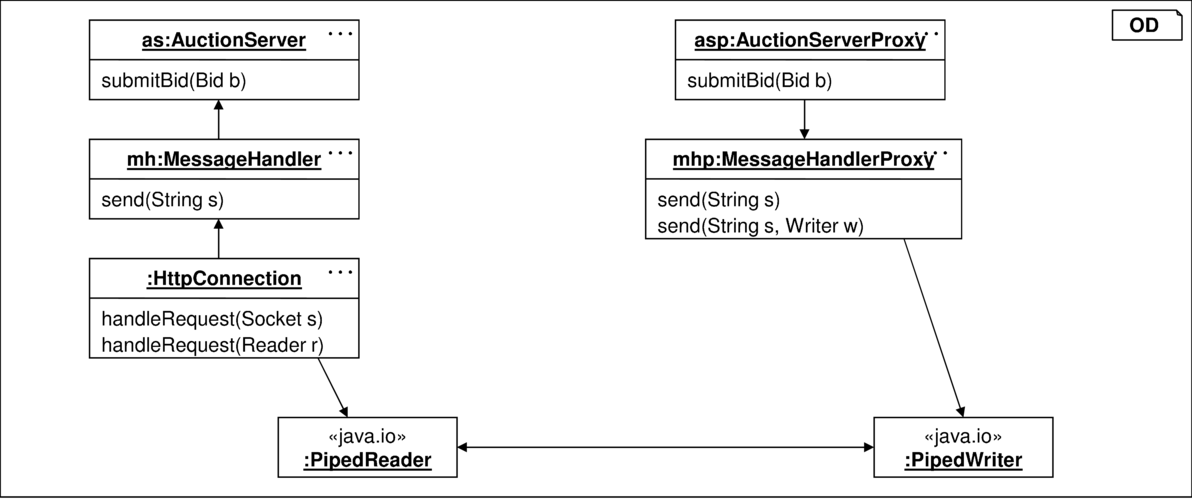
Testtreiber sind für die verschiedenen Konfigurationen teilweise wiederverwendbar, müssen aber unter Umständen angepasst werden. So ist in der Konfiguration aus Abbildung 8.29 sicherzustellen, dass die in der Pipe abgelegten Daten wieder ausgelesen werden. Das heißt, HttpConnection ist entsprechend oft zu aktivieren. In der in Abbildung 8.27 dargestellten Konfiguration entfällt dieser Zusatzaufwand für den Treiber.
8.5.5 Muster für Verteilung und Kommunikation
Die Simulation von Verteilung und der sich daraus ergebende Aufwand für statische Variablen und Kommunikation kann in dem Muster aus Tabelle 8.30 zusammengefasst werden.
|
|
|
|
Muster: Verteilung und Kommunikation
|
|
|
|
|
| Intention | Echte Verteilung ist sehr schwer zu testen und verteilte Testläufe sind zeitaufwändig. Aus Effizienzgründen ist es deshalb sinnvoll, Verteilung in einem Prozessraum zu simulieren. |
|
|
|
| Anwendung |
Eine Anwendung dieses Musters ist sinnvoll, wenn
|
|
|
|
| Struktur | Es werden Lokationen (Tabelle 8.24) benutzt, um die physische Verteilung zu modellieren. |
| Statische Variablen und Factories werden mit dem Muster 8.25 für die Lokationen individualisiert und in der Implementierung wird verborgen, welche Lokation gerade aktiv ist. | |
| Die Kommunikation wird entsprechend der nachfolgenden Klassenstruktur aufgebaut. Verschiedene Konfigurationen erlauben den flexiblen Einsatz im Produktionssystem und in Testfällen. | |
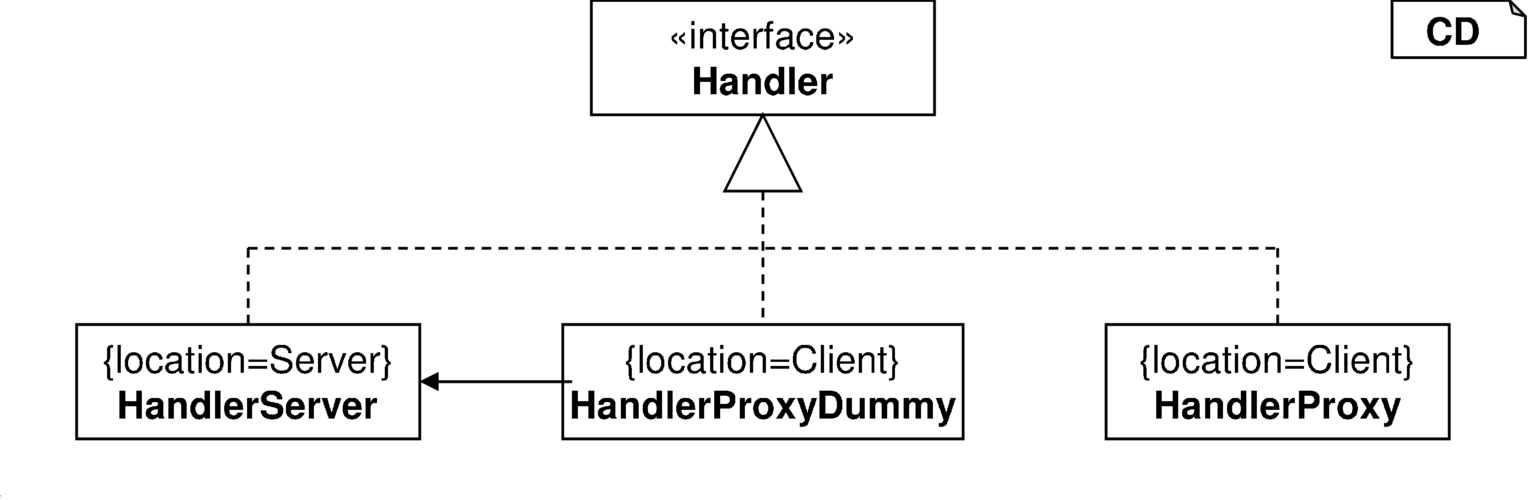 |
|
|
|
|
| Implementierung Dummy | Im Wesentlichen wird vom Dummy direkt zum Server delegiert, wobei unter Umständen als Argumente angegebene Objektstrukturen zu kopieren beziehungsweise die in der jeweiligen Lokation bereits vorhandenen Duplikate zu verwenden sind. |
| Der Dummy wirkt als Schnittstelle zwischen verschiedenen Lokationen und ist daher verantwortlich für den Wechsel des Prozesskontexts bei Aufruf des Servers und dessen Return. | |
|
|
|
| Beachtenswert | Der Server muss nicht notwendigerweise dasselbe Interface wie das Proxy realisieren. Dann ist der Umsetzungsaufwand im Dummy entsprechend größer. |
|
|
|
|
Tabelle 8.30: Muster: Verteilung und Kommunikation
|
|
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |