Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
1.1 Ziele der beiden Bücher
1.2 Überblick
1.3 Notationelle Konventionen
1.4 Einordnung der UML/P
1.5 Ausblick: Agile Modellierung mit UML
2 Klassendiagramme
3 Object Constraint Language
4 Objektdiagramme
5 Statecharts
6 Sequenzdiagramme
A Sprachdarstellung durch Syntaxklassendiagramme
B Java
C Die Syntax der UML/P
D Anwendungsbeispiel: Internet-basiertes Auktionssystem
Literatur
| << zurück | MBSE Home | weiter >> |
1.4 Einordnung der UML/P
1.4.1 Bedeutung und Anwendungsbereiche der UML
Graphische Notationen haben gegenüber textuellen Darstellungsformen speziell bei der Kommunikation zwischen Entwicklern eine Reihe von Vorteilen. Sie erlauben dem Betrachter einen schnellen Überblick zu erhalten und erleichtern das Erfassen von miteinander in Beziehung stehenden Systemteilen. Aufgrund ihrer zweidimensionalen Natur besitzen graphische Beschreibungstechniken jedoch auch Nachteile. Genannt seien hier der sehr viel größere Platzverbrauch, also die geringere Informationsdichte, die insbesondere bei großen Modellen leicht zum Verlust des Überblicks führt und die allgemein als schwieriger angesehene präzise Definition der Syntax und Semantik einer graphischen Sprache.
Mit der Durchdringung des objektorientierten Programmierparadigmas in nahezu alle Bereiche der Software- und Systementwicklung und der parallel immer komplexer werdenden Systeme sind eine Reihe objektorientierter Modellierungsansätze definiert worden.
Die Unified Modeling Language (UML) [OMG10a] ist der erfolgreiche Versuch, die unterschiedlichen Notationen zu vereinheitlichen und damit eine Standard-Modellierungssprache für die Softwareentwicklung zu entwerfen. Die UML hat mittlerweile einen hohen Verbreitungsgrad. Wesentlich war dabei die Trennung zwischen der Vorgehensweise und der zugrunde liegenden Notation. Die UML ist dazu gedacht, als Beschreibungstechnik für möglichst alle Anwendungsbereiche der Softwareentwicklung zur Verfügung zu stehen. Entsprechend ist auch das in diesem Buch definierte UML/P-Sprachprofil zum Teil methodenneutral, obwohl es sich in besoderem Maße für generative Projekte mit Java als Zielsprache eignet. Dies zeigen auch neuere Bücher, die sich auch mit der Beziehung zwischen der UML und einer Programmiersprache wie etwa Java beschäftigen [Lan09, Lan05].
Mit der UML ist eine Integration eines Teils der bisherigen Vielfalt an Modellierungssprachen erreicht worden. Syntaktische Unterschiede wurden harmonisiert und Konzepte aus verschiedenen Bereichen in die Gesamtsprache integriert. Obwohl dadurch eine sehr große, teilweise überladene Sprache entstanden ist, kann davon ausgegangen werden, dass die UML zumindest ein Jahrzehnt eine wesentliche Rolle als Sprachstandard beanspruchen wird.
1.4.2 UML-Sprachprofile
Die UML wird mittlerweile nicht mehr als in allen syntaktischen und semantischen Einzelheiten vollständig definierte Sprache, sondern als Sprachrahmen oder als Familie von Sprachen verstanden [CKM+99, Grö10, GRR10], die es aufgrund von Erweiterungsmechanismen und semantischen Variationsmöglichkeiten erlaubt, Sprachprofile auszubilden, die dem jeweiligen Einsatzzweck angepasst werden können. Damit erhält die UML Charakteristika einer Umgangssprache wie zum Beispiel Deutsch, die es ebenfalls erlaubt, das Vokabular in Form von Fachsprachen und Dialekten anzupassen.
Bereits in [OMG99] wurden die wesentlichen Anforderungen für ein Profil-Konzept für die UML festgelegt und in [CKM+99] diskutiert, wie sich dies auf die Ausprägung unternehmens- oder projektspezifischer Sprachprofile auswirkt.
[Grö10, GRR10] zeigt wie die Organisation syntaktischer und semantischer Variabilitäten eines Teils der UML in Form von Features und Sprachkonfigurationen dargestellt und für die Konfiguration einer Sprache passend zum Projekt eingesetzt werden kann.
Beispiele für Sprachprofile sind die Spezialisierung der UML auf Echtzeitsysteme [OMG09], auf Enterprise Distributed Object Computing (EDOC) [OMG04], Multimedia-Anwendungen [SE99b, SE99a] und Frameworks [FPR01]. Die Erweiterbarkeit der UML wird durch mehrere Mechanismen auf verschiedenen Ebenen erreicht. Neues Vokabular wird durch Benennung von Klassen, Methoden, Attributen oder Zuständen direkt im Modell eingeführt. Profile bieten zusätzlich „light-weight“-Erweiterungen der UML-Syntax, wie die in Abschnitt 2.5 diskutierten Stereotypen und Merkmale, und „heavy-weight“-Erweiterungen mit neuen Modellierungskonstrukten.1
Laut [OMG99] ist das Konzept zur Profildefinition für die UML unter anderem dafür vorgesehen:
- Präzise Definition von Merkmalen, Stereotypen und Bedingungen (Constraints) ist möglich.
- Die Beschreibung von Semantik in natürlicher Sprache ist zugelassen.
- Ein spezifischeres Profil kann ein allgemeineres Profil für die gewünschte Einsatzform anpassen.
- Die Kombination von Profilen erlaubt die gleichzeitige Verwendung mehrerer Profile.
- Mechanismen zum Management der Kompatibilität von Profilen werden angeboten.
Der Wunsch nach leichter Austauschbarkeit und Kombinierbarkeit von Sprachprofilen ist jedoch nicht leicht zu erfüllen. Im Gegenteil können werkzeugbasierte Sprachprofile normalerweise nur dann kombiniert werden, wenn diese explizit aufeinander abgestimmt sind.
1.4.3 Die Notationen in der UML/P
Die UML/P besteht, wie in Abbildung 1.3 illustriert, aus sechs Teilnotationen. Dabei fehlen einige Teilnotationen des UML-Standards. UML/P ist ein Sprachprofil, das besonders die Aktivitäten Entwurf, Implementierung und Weiterentwicklung unterstützt, weil UML/P auch als vollständige Programmiersprache verwendet werden kann. Deshalb wurde das Sprachprofil mit dem Suffix „/P“ für „Programmier-geeignet“ gewählt.
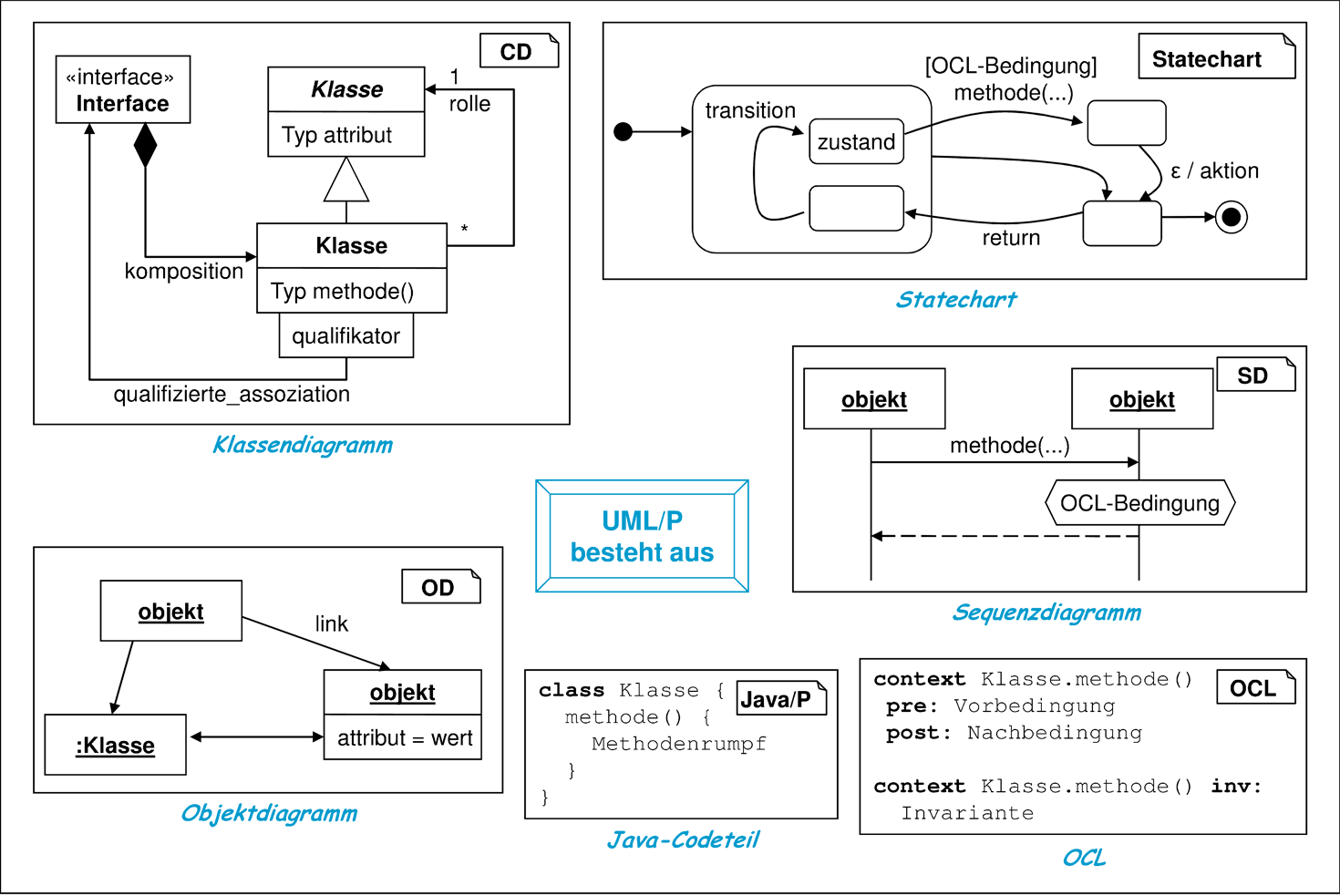
Die Eignung zur Programmiersprache ist nicht zuletzt auf die Integration von Java-Codestücken in die UML/P und die Anpassung textueller Teile der UML/P auf die Java-Syntax zurückzuführen.
Die im vorhergehenden Abschnitt 1.4.2 diskutierte Notwendigkeit zur Einführung von weiteren, spezialisierenden Sprachprofilen wird in UML/P durch die Konkretisierung der Definition von Stereotypen und Merkmalen ermöglicht. Beide Formen zur Anpassung von Sprachelementen werden zur Definition der UML/P selbst genutzt, stehen aber auch für weitere Anpassungen zur Verfügung, so dass die UML/P als Ausgangsbasis für die Definition weiterer, anwendungs-, domänen- oder technikspezifischer Sprachprofile geeignet ist.
1.4.4 Modellbegriff und Modellbasierung
Der Modellbegriff
Der Begriff „Modell“ wird in der Softwaretechnik für eine Reihe verschiedener Konzepte eingesetzt. So gibt es unter anderem Produktmodelle, Vorgehensmodelle oder Testmodelle. Eine gute Kategorisierung dieser Begriffe ist in [SPHP02, Sch00] zu finden. Abbildung 1.4 gibt eine Übersicht über allgemeine Definitionen des Begriffs „Modell“. Generell anerkannt ist die Abstraktion, die ein Modell gegenüber dem modellierten Gegenstand besitzt, indem zum Beispiel Details weggelassen werden. Sinnvoll, aber nicht in allen Definitionen Voraussetzung ist auch der zielorientierte Einsatz eines Modells.
- Ein Modell ist seinem Wesen nach eine in Maßstab, Detailliertheit und/oder Funktionalität verkürzte beziehungsweise abstrahierte Darstellung des originalen Systems (nach [Sta73]).
- Ein Modell ist eine Abstraktion eines Systems mit der Zielsetzung das Nachdenken über ein System zu vereinfachen, indem irrelevante Details ausgelassen werden (nach [BD00].
- Ein Modell ist eine „vereinfachte, auf ein bestimmtes Ziel hin ausgerichtete Darstellung der Funktion eines Gegenstands oder des Ablaufs eines Sachverhalts, die eine Untersuchung oder eine Erforschung erleichtert oder erst möglich macht“ [Bal00].
- In der Softwaretechnik ist ein Modell eine idealisierte, vereinfachte, in gewisser Hinsicht ähnliche Darstellung eines Gegenstands, Systems oder sonstigen Weltausschnitts mit dem Ziel, bestimmte Eigenschaften des Vorbilds daran besser studieren zu können (nach [HBvB+94]).
Uneinigkeit herrscht im Allgemeinen über die Granularität eines Modells. So spricht [Bal00] einerseits von einem vollständigen Produktmodell und assoziiert damit eine Sammlung von Diagrammen und andererseits vom Modell als Artefakt, das ein Modell eher einem einzelnen Diagramm gleichsetzt. Auch in diesem Buch wird der Begriff „Modell“ in einem weiteren Sinn verwendet und auch ein Klassendiagramm oder ein Statechart als Modell eines Ausschnitts des zu realisierenden Systems bezeichnet.
Ein Modell hat grundsätzlich Bezug zu einem Vorbild oder Original. In der Softwaretechnik werden aber Modelle häufig vor dem Original gebildet. Außerdem kann aufgrund der Immaterialität von Software aus einem Modell durch automatisches Hinzufügen von Details das vollständige System ohne manuelles Zutun entstehen.
Modellbasierte Softwareentwicklung
In Abschnitt 2.4 wird der Begriff Sicht als dem Entwickler zugängliche Repräsentation zum Beispiel eines Produktmodells identifiziert. Die dabei stattfindende zweistufige Modellabstraktion vom System über das vollständige Modell zur Entwicklersicht ist in der Größe des Systems begründet. Ein vollständiges Produktmodell hat normalerweise eine Komplexität, die es nicht mehr ohne weiteres erlaubt, Zusammenhänge zu erkennen. Deshalb werden mit den Sichten Ausschnitte des Produktmodells gebildet, die bestimmte Aspekte betonen, andere aber auslassen. Eine Sicht ist ebenfalls ein Modell und als solches zielgerichtet. Eine Sicht wird gebildet, um eine „Story“ zu kommunizieren. Ein Produktmodell kann als die Summe seiner Sichten verstanden werden. Demgegenüber hat zum Beispiel [SPHP02] einen engeren Modellbegriff, indem es Sichten nicht als eigenständige Modelle betrachtet. Entsprechend werden alle dort diskutierten Test- und Refactoring-Techniken direkt auf dem alles umfassenden Produktmodell formuliert.
Während diese Abstraktionsstufen der Modellbildung aus Entwicklersicht allgemein anerkannt sind, herrschen bei den Werkzeugherstellern heute zwei Ansätze zur technischen Realisierung vor:
- Die Modellbasierung erfordert, dass ein vollständiges und konsistentes Modell des Systems im Werkzeug verwaltet wird, und erlaubt nur Entwicklungsschritte, die an diesem Modell und allen seinen darin enthaltenen Sichten in konsistenter Weise vorgenommen werden.
- Die Dokumentorientierung erlaubt es, jede einzelne Sicht als eigenständiges Dokument zu bearbeiten. Inkonsistenzen innerhalb sowie zwischen Dokumenten werden zunächst gestattet und erst beim Aufruf von entsprechenden Analysewerkzeugen erkannt.
Beide Ansätze haben spezifische Vor- und Nachteile. Die Vorteile des modellbasierten Ansatzes sind:
- Automatische Sicherung der Konsistenz eines Modells ist nur in der modellbasierten Form zu erhalten. Im dokumentorientierten Ansatz kostet die Analyse Zeit, die zum Beispiel die Codegenerierung verlangsamt.
- Werkzeuge sind einfacher zu implementieren, da sie keine Techniken wie Verschmelzung mehrerer Klassendiagramme oder Statecharts für dieselbe Klasse anbieten müssen.
Dem stehen folgende Vorteile des dokumentorientierten Ansatzes und Nachteile der Modellbasierung gegenüber:
- Aus den Erfahrungen mit den syntaxgesteuerten Editoren für Programmiersprachen hat sich gezeigt, dass Unterstützung hilfreich ist, während syntaxgesteuerte Editoren den Gedankenfluss und die Effizienz des Entwicklers stören. Im dokumentorientierten Ansatz lassen sich vorübergehende Inkonsistenzen und syntaktisch fehlerhafte Dokumente besser tolerieren.
- In großen Projekten mit mehreren Entwicklern sind bei modellbasierten Werkzeugen Maßnahmen zu treffen, die die permanente Konsistenz des gleichzeitig bearbeiteten Modells herstellen. Dazu gehören ein gemeinsames Repository mit Synchronisations- oder Locking-Mechanismen. Während erstere Ineffizienzen mit sich bringen, untersagen letztere einen gemeinsamen Modellbesitz und verhindern Agilität.
- Eine permanente Synchronisation der Modelle über ein Repository verbietet die lokale Erprobung von Alternativen. Deshalb muss ein Transaktionskonzept, eine Versionskontrolle oder ein ähnlicher Mechanismus vom Repository angeboten werden, wodurch faktisch ebenfalls das Problem der Integration von Modellversionen entsteht.
- Demgegenüber sind im dokumentorientierten Ansatz Integrationstechniken parallel bearbeiteter Modellteile zu verwenden, wie sie etwa bei Versionsverwaltungen eingesetzt werden. Diese Integration ist notwendig, wenn der Entwickler seine lokal bearbeitete Fassung in die Versionsverwaltung zurückspielt und damit für andere Projektteilnehmer publiziert. Lokale Experimente bleiben damit folgenlos, wenn sie nicht publiziert werden.
- Für selbst entwickelte Spezialwerkzeuge ist es im Allgemeinen einfacher, einzelne, dateibasierte Dokumente zu bearbeiten, als komplette, im Repository abgespeicherte und einer Versions- oder Transaktionskontrolle unterliegende Modelle.
- Ein inkrementeller, modularer Ansatz zur Verarbeitung von Modellen, insbesondere bei der Generierung kann die Effizienz in der Entwicklung deutlich erhöhen, weil so nur Modelle eingelesen und dafür Code neu generiert werden muss, wenn sie sich verändert haben. Dies erfordert aber eine Modularität für UML-Modelle, in dem Sinn, dass die zwischen Modellen auszutauschende Information im Sinne von Schnittstellen zu klären und analog zu Programmiersprachen auch eigenständig abzulegen sind.
In der Praxis dürfte sich jedoch ein synergetischer Kompromiss beider Ansätze als der ideale Weg herauskristallisieren. Im Bereich der Bearbeitung von Programmiersprachen mit integrierten Entwicklungsumgebungen (IDE’s) zeichnet sich dies bereits ab. Eine IDE beinhaltet einen Editor mit syntaxgesteuerten Hervorhebungen, Navigation und Ersetzungsmöglichkeiten bis hin zu automatischen Analysen und Codegenerierung im Hintergrund. Die Ablage der Informationen erfolgt allerdings artefaktbasiert in einzelnen Dateien, die gegebenenfalls durch zusätzliche und automatisch erstellte Tabellen unterstützt werden. Damit bleiben die einzelnen Dateien auch für andere Werkzeuge zugänglich, aber beim Entwickler entsteht der Eindruck einer modellbasierten Entwicklungsumgebung. Vorteilhaft ist auch, dass die Entwickler selbst wählen können, welche Dateien und damit welchen Teil des „Modells“ sie im Werkzeug laden und bearbeiten möchten.
Model Driven Architecture (MDA)
Der „Model Driven Architecture“-Ansatz (MDA) [OMG03, PM06, GPR06] ist eine Weiterführung der Standardisierungsideen der Object Management Group (OMG), der unter anderem auf der UML basiert. Eine der Kernideen dieses Ansatzes ist im ersten Schritt der Entwicklung die Definition plattformunabhängiger Modelle der Geschäftsanwendung mit der UML. Davon getrennt erfolgt im zweiten Schritt die Abbildung dieses plattformunabhängigen Modells auf eine Realisierung mit konkreter Hardware, vorgegebenen Betriebssystemen, Middleware- und Framework-Komponenten.
Dadurch wird die Entwicklung des plattformunabhängigen UML-Modells von plattformspezifischen Konzepten entkoppelt. Die Implementierung besteht dann aus einer Abbildung des plattformunabhängigen auf ein plattformspezifisches UML-Modell, das in einem entsprechenden UML-Sprachprofil formuliert wird. Dafür sollen zum Beispiel Corba-spezifische UML-Profile zur Verfügung stehen. Dann erfolgt die möglichst weit automatisierte Abbildung dieses Modells in eine Implementierung und entsprechende Schnittstellendefinitionen. Neben den technologiespezifischen Abbildungen werden in der MDA auch Standardisierungsbemühungen für Anwendungsdomänen einbezogen. Dazu gehören zum Beispiel die XML-basierten Kommunikationsstandards für E-Commerce, Telekommunikation oder dem Datenmodell für die Finanzindustrie.
MDA basiert einerseits auf der Beobachtung, dass Geschäftsanwendungen durchschnittlich sehr viel länger leben als technologische Plattformen und daher des öfteren eine Migration von Anwendungen notwendig ist. Andererseits basiert MDA auf der Hoffnung, damit sowohl die Wiederverwendung beziehungsweise Evolution applikationsspezifischer Modelle für ähnliche Anwendungen als auch die Interoperabilität zwischen Systemen zu vereinfachen.
In seiner Gänze ist MDA ein Ansatz, der sowohl die Werkzeuge zur Softwareentwicklung als auch die Vorgehensweise zu deren Definition revolutionieren will und sich insbesondere mit der unternehmensweiten und unternehmensübergreifenden Vernetzung von Systemen auseinandersetzt [DSo01, GPR06]. Interessanterweise ist zwar an eine signifikante Reduktion des Aufwands zur Softwareentwicklung durch Generierung beabsichtigt, jedoch werden dazu passende Methodiken nur wenig diskutiert.
Auch der im zweiten Band diskutierte Ansatz kann als eine Konkretisierung eines Teils der MDA verstanden werden. Im Gegensatz zur MDA soll aber kein a priori alles umfassender Ansatz unter Einbeziehung beispielsweise von Metamodellierung, allen verfügbaren Middleware-Techniken oder der Interoperabilität zwischen Applikationen vorgestellt werden. Stattdessen wird hier im Sinne von XP eher die einfache, aber effektivere Lösung vorgeschlagen, in der nur die Schnittstellen bedient, nur die Middleware-Komponenten eingesetzt und nur die Betriebssysteme beachtet werden, für die das System jetzt zu entwickeln ist. Es ist anzunehmen, dass die Verfügbarkeit von standardisierten Abbildungen von plattformunabhängigen Modellen auf die jeweilige Technologie für weite Bereiche unwahrscheinlich sein wird. Im Allgemeinen werden diese Abbildungen auf Basis vorgefertigter Muster selbst zu entwickeln und daher Codegeneratoren entsprechend zu parametrisieren sein. Entsprechend sollte Einfachheit vor die Bedienung unnötiger Standards gestellt werden.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |