7.3 Methodenspezifikationen
Eines der wesentlichen Anwendungsgebiete der OCL ist die Beschreibung des Verhaltens einzelner Methoden auf abstrakte Weise, indem für die Methode eine Vorbedingung und eine
Nachbedingung angegeben werden. Eine Methodenspezifikation kann als Codeinstrumentierung, als Teil eines Testfalls und als Ausgangspunkt zur Ableitung von Testdatensätzen dienen.
7.3.1 Methodenspezifikationen als Codeinstrumentierung
Das Paar CC2pre/CC2post ist ein typisches Beispiel für eine Methodenspezifikation. Es wurde aus Abschnitt 3.4.3, Band 1 übernommen. Dessen
Kontext ist bereits dort beschrieben:
OCL
 context Person.changeCompany(String name) context Person.changeCompany(String name) |
| pre CC2pre: company.name != name && |
| exists Company co: co.name == name |
| company.employees == company.employees@pre +1 && |
| company@pre.employees == company@pre.employees@pre -1 |
Eine typische Umsetzung dieser Methodenspezifikation ist die Instrumentierung des Produktionscodes analog der in Abschnitt 7.2
beschriebenen Verwendung von Zusicherungen. Abbildung 7.6 zeigt einen Methodenrumpf der Methode changeCompany
für einen der drei nachfolgend noch diskutierten Fälle, der um ocl-Anweisungen angereichert wurde.
Die ocl-Anweisungen und ihre OCL-Argumente werden, wie bereits in Abschnitt 7.2 diskutiert, in
JUnit-fähige Laufzeitprüfungen umgesetzt. Die für die Laufzeit problematische Existenzquantifizierung in der OCL-Bedingung kann effizienter gestaltet werden, indem die
Methodenspezifikation so umgestaltet wird, dass statt der Existenzquantifizierung mittels let-Konstrukt direkt das infrage kommende Company-Objekt festgelegt wird.
7.3.2 Methodenspezifikationen zur Testfallbestimmung
Mit der obigen Umsetzung ist zwar die Methodenspezifikation zur Instrumentierung des Produktionscodes verwendet worden, ein Testfall beziehungsweise dessen operative Umsetzung in
einen Testtreiber ist aber damit nicht entstanden. Die Entwicklung von Tests aus einem Vor-/Nachbedingungspaar ist generell nicht einfach. Jedoch lassen sich für bestimmte Formen von Methoden
aus der Struktur der Spezifikation geeignete Testdatensätze ableiten.
Ausgehend von der disjunktiven Normalform der Vorbedingung kann eine Partitionierung vorgenommen werden, die es erfordert, pro erfüllbarer Klausel der Normalform einen Testfall zu
definieren. In [BW02a, BW02b] wurde dies an einem Beispiel durch Transformation nach Isabelle/HOL
[NPW02] vorgenommen um mit einem Verifikationswerkzeug zumindest teilweise automatisiert nicht erfüllbare Anteile zu erkennen
und zu eliminieren. Das Beispiel changeCompany mit seinen drei Spezifikationsteilen (siehe Abschnitt 3.4.3, Band 1) kann ebenfalls als Disjunktion verstanden werden.
Diese Methode ist durch drei Vor-/Nachbedingungspaare beschrieben, die drei Äquivalenzklassen CC1pre, CC2pre und CC3pre von Eingaben festlegen:
OCL
 // Liste von Vorbedingungen als OCL-Teile // Liste von Vorbedingungen als OCL-Teile |
| context Person.changeCompany(String name) |
| pre CC1pre: !exists Company co: co.name == name |
| pre CC2pre: company.name != name && |
| exists Company co: co.name == name |
| pre CC3pre: company.name == name |
Diese Äquivalenzklassen sind paarweise disjunkt und partitionieren den gesamten möglichen Eingabebereich. Die Disjunktion der drei Bedingungen ergibt:
OCL
 CC1pre || CC2pre || CC3pre <=> true CC1pre || CC2pre || CC3pre <=> true |
Zumindest ein Testfall sollte daher für jede dieser drei Äquivalenzklassen zur Verfügung gestellt werden. Die Identifikation von Äquivalenzklassen für Testdaten ist ein
wesentlicher Schritt zur systematischen Entwicklung von Tests. Auf Basis einer manuellen oder werkzeuggestützten Analyse der Spezifikation können interessante Testfälle ermittelt
werden. Leider ist davon auszugehen, dass die Generierung von Testdatensätzen, in diesem Beispiel also Objektstrukturen, in denen jeweils eine der angegebenen Bedingungen gilt, nicht ohne
weiteres automatisierbar ist. Beispielsweise ist die konstruktive Umsetzung des Existenzquantors exists x: P, also die Generierung von Code, der ein Objekt x erzeugt, das die Bedingung P erfüllt, nur für Spezialfälle von P lösbar. Dennoch ist es hilfreich,
bei der Analyse einer gegebenen Testsammlung einen Hinweis zu erhalten, wenn eine der angegebenen Äquivalenzklassen durch Tests nicht abgedeckt wird.
Wie in [Mye01, Lig90, Bal98] beschrieben, kann die Partitionierung des
Testdatenraums durch eine Analyse der Nachbedingungen verfeinert werden. Dazu wird folgende Spezifikation betrachtet:
OCL
 context int abs(int val) context int abs(int val) |
| post: if (val>=0) then result==val else result==-val |
Da die Vorbedingung true ist, kann sie für keine Partitionierung des Testdatenraums genutzt werden. In diesem Fall kann aber eine Analyse der Nachbedingung
helfen, die sofort zwei Äquivalenzklassen erkennen lässt: val>=0 und val<0.
Eine weitere Möglichkeit zur Testfalldefinition bilden die standardmäßige Äquivalenzklassenbildung und die Betrachtung von Grenzwertfällen. Dies eignet sich besonders
für die von der Programmiersprache angebotenen Datentypen. Zum Beispiel bietet es sich für ganze Zahlen an, Testdaten aus Set{-n,-10,-2,-1,0,1,2,3,4,10, 11,n+1} (für ein großes n des Wertebereichs) zu
verwenden, da meist kritische Sonderfälle im Bereich um die 0 zu finden sind. Für Container-Datenstrukturen, boolesche Werte und Fließkommazahlen lassen
sich ähnliche Standards festlegen.
Diese Standardfälle leiten sich aus der Erkenntnis her, dass in diesen Datentypen ausgezeichnete Werte existieren, bei denen die Implementierung einen anderen Pfad nimmt, als bei
benachbarten Werten. Das Verfahren der Grenzwertanalyse [Mye01, Bal98] grenzt explizit solche
Wertebereiche ein und deckt sie durch Testdatensätze auf jeder Seite der Grenze ab. Im Fall der Absolutfunktion ist die 0 eine solche Grenze und erfordert
-1, 0, +1 als Testdaten. Meist ist jedoch die Feststellung der Grenzwerte komplexer, da Fallunterscheidungen
die Parameter in Beziehung setzen können.
Neben der Entwicklung von Black-Box-Tests aus der Spezifikation darf aber auch die Entwicklung von White-Box-Tests aus einer gegebenen Implementierung nicht vernachlässigt werden. Erst
durch eine Analyse der Implementierung, in diesem Fall also vor allem der Java-Coderümpfe und Transitions-Aktionen, werden zusätzliche Fälle offensichtlich, die in der Spezifikation
eventuell nicht erkennbar waren. Hier sind klassische Techniken zur Testüberdeckung einzusetzen [Bei95, Bal98].
In manchen Fällen lässt sich die Menge und Art notwendiger Testfälle aus einer Spezifikation nicht vorhersagen, weil es eine Reihe unterschiedlicher Implementierungen gibt. Dazu
gehören zum Beispiel Sortierverfahren, wie Mergesort, Quicksort oder Bubblesort, die jeweils sehr unterschiedlich funktionieren und deshalb unterschiedliche Testdatensätze erfordern.
Besonders aufwändig werden Tests für Kombinationen, indem etwa Bubblesort für das Vorsortieren kleiner Reihungen vor der Anwendung von Mergesort verwendet wird.
Allgemein ist es aber wichtig, dass Testfälle sowohl auf Basis einer Codeanalyse als auch aus der Spezifikation entwickelt werden. Denn codebasierte Tests sind vor allem zur Sicherung der
Robustheit geeignet, während spezifikationsbasierte Tests die Übereinstimmung des implementierten und des spezifizierten Verhaltens, also der Spezifikationskonformität, prüfen.
Ist zum Beispiel bei der Implementierung ein Spezifikationsfall vergessen worden (eine Auslassung), so kann dies durch codebasierte Testfälle nicht entdeckt
werden.
Jedoch ist auch bei der schematischen Verwendung von Metriken zur Testfallüberdeckung Vorsicht geboten, da diese dazu führen können, die Metriken zu schematisch zu erfüllen
und einerseits doch wichtige Fälle zu übersehen, andererseits aber viel, eventuell unnötigen Zusatzaufwand erzeugen. Generell ist daher eine an die Komplexität des Testlings und
die notwendige Qualität des Systems angepasste Kombination aus verschiedenen Vorgehensweisen zur Testfalldefinition als optimal anzusehen.
7.3.3 Testfalldefinition mit Methodenspezifikationen
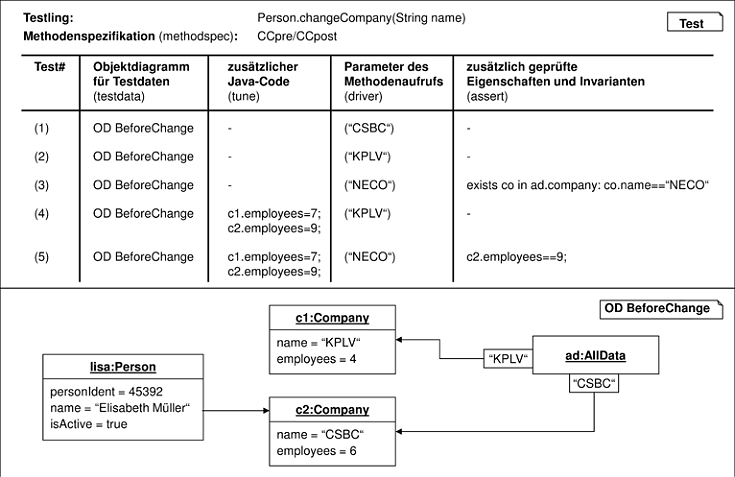
Eine Methodenspezifikation stellt noch keinen vollständigen Testfall dar, sondern benötigt zusätzlich einen Testdatensatz. Abbildung 7.7 zeigt eine tabellarische Darstellung einer Testfallsammlung, bestehend aus fünf Testfällen, aus der automatisch eine Testsuite für JUnit generiert
werden kann.
Dabei kann für die ersten drei Fälle dasselbe Objektdiagramm als Testdatensatz verwendet werden, denn es können alleine durch den Aufruf-Parameter alle drei Fälle variiert
werden. Für die Fälle (4) und (5) wird zusätzlicher Java-Code verwendet, der nach Aufbau des Objektdiagramms, aber vor dem Test selbst ausgeführt wird. Beide Fälle stellen
Varianten bereits vorhandener Fälle dar. Sie prüfen vor allem die korrekte Änderung der Zahl der Angestellten. Dies erscheint notwendig, denn sonst hätte eine Implementierung
die Angestelltenzahl immer auf denselben Wert setzen können, ohne dass dies entdeckt worden wäre.
Durch die Möglichkeit, zusätzliche OCL-Bedingungen oder Invarianten (per Namen) anzugeben, können weitere Eigenschaften geprüft werden. So wird in Fall (3) gefordert, dass
die neue Firma auch im Singleton ad angemeldet ist, und im Fall (5) beschrieben, dass die unbeteiligte Firma „KPLV“ die Anzahl ihrer am System angemeldeten
Angestellten beibehält. Beides hätte auch jeweils durch Objektdiagramme ausgedrückt werden können.
Das angegebene Objektdiagramm BeforeChange wird konstruktiv eingesetzt, denn daraus werden die Testdaten generiert. Das Objektdiagramm gibt hier also sogar die
komplette Umgebung an, es existieren keine weiteren Person- und Company-Objekte. Deshalb verletzt der im Attribut employee angegebene Wert Invarianten, die deshalb bei diesem Test nicht geprüft werden dürfen.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
 class Person {
class Person {