Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
5 Transformationen für die Codegenerierung
5.1 Übersetzung von Klassendiagrammen
5.2 Übersetzung von Objektdiagrammen
5.3 Codegenerierung aus OCL
5.4 Ausführung von Statecharts
5.5 Übersetzung von Sequenzdiagrammen
5.6 Zusammenfassung zur Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
5.1 Übersetzung von Klassendiagrammen
In diesem Abschnitt wird die Transformation von Konzepten des Klassendiagramms und einiger damit zusammenhängender Elemente in Java als komplexeres Beispiel durch eine Sammlung von Transformationsregeln beschrieben, die auch die Möglichkeiten zur Beschreibung von Alternativen und von Kompositionen der Regeln zeigen. Bei dieser Übersetzung werden weder Java-Frameworks oder Infrastrukturkonzepte wie JavaBeans oder Middleware-Komponenten noch Datenbank-Anbindungen berücksichtigt. Dafür sind jeweils spezielle Generatoren notwendig, die in der hier angestrebten allgemeinen Form nicht diskutiert werden können.
5.1.1 Attribute
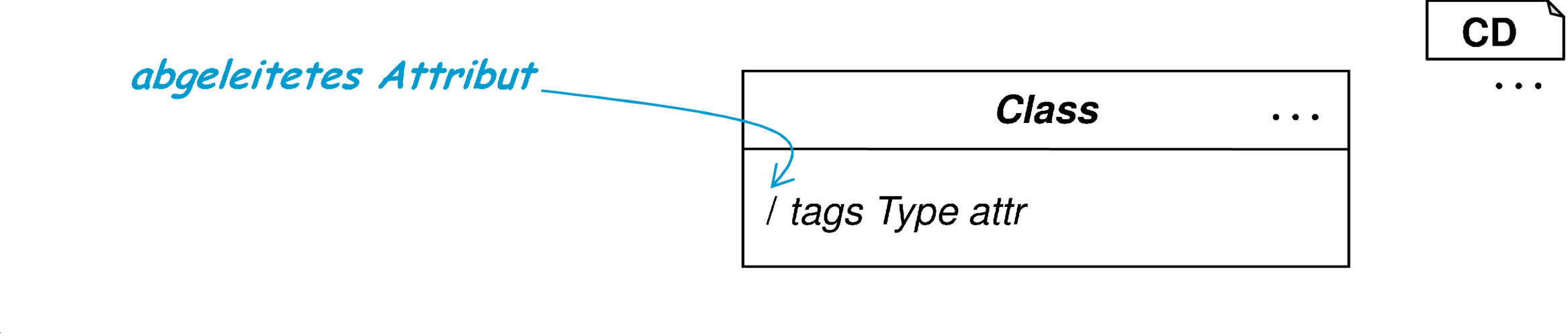
Für normale und statische Attribute von Klassen wurde mit der Transformationsregel von Abbildung 4.12 bereits eine Regel zur Umsetzung angegeben. Diese kann im Prinzip auch für abgeleitete Attribute verwendet werden, ignoriert jedoch ein wesentliches Merkmal dieser Art von Attributen. Im Normalfall existiert für ein abgeleitetes Attribut eine als Invariante formulierte Berechnungsvorschrift. Alternativ dazu kann auch eine bereits in der Zielsprache Java formulierte Methode existieren, die die Berechnung des Attributs vornimmt. Nach unserer Konvention heißt eine solche Methode calcAttr.
|
|
|
||||||||||||||
|
Attribut2eager: Abgeleitete Attribute - Eager Version
|
|||||||||||||||
|
|
|
||||||||||||||
|
Erklärung |
Für ein abgeleitetes Attribut /attr existiert eine Berechnungsvorschrift als OCL-Invariante der Form attr=expr oder eine Methode calcAttr. Änderungen der zur Berechnung verwendeten Attribute treten gegenüber der Abfrage des abgeleiteten Attributs selten auf. Deshalb wird das abgeleitete Attribut sofort neu berechnet und gespeichert. |
||||||||||||||
|
|
|||||||||||||||
|
Attributdefinition |
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|||||||||||||||
|
Attributzugriff |
|
||||||||||||||
|
|
|||||||||||||||
|
Attributbesetzung |
ist nicht möglich. |
||||||||||||||
|
|
|||||||||||||||
|
Besetzung eines Ausgangsattributs |
durch Analyse des OCL-Ausdrucks beziehungsweise der vorhandenen calcAttr-Implementierung können die Ausgangsattribute ermittelt werden, von denen attr abgeleitet ist. Für jedes Ausgangsattribut source wird die set-Methode erweitert: |
||||||||||||||
|
|
|
||||||||||||||
|
|
|||||||||||||||
|
Beachtenswert |
Die Veränderung eines Attributs hat die automatische Veränderung aller davon abgeleiteten Attribute zur Folge. Dies kann zu kaskadenartigen Neuberechnungen abgeleiteter Attribute führen und ineffizient sein, wenn mehr Änderungen als Abfragen auftreten. Zirkuläre Abhängigkeiten führen darüber hinaus zu nichtterminierenden Neuberechnungen und sind daher verboten. |
||||||||||||||
|
|
|
||||||||||||||


Der oben formulierten „eager“ Version der Umsetzung kann eine „lazy“ Version entgegengesetzt werden, die den Attributwert nur bei Bedarf berechnet. Aufgrund der Ähnlichkeiten zur vorherigen Transformationsregel wird diese verkürzt wiedergegeben:
|
|
|
|||||||||||||
|
Attribut2lazy: Abgeleitete Attribute - Lazy Version
|
||||||||||||||
|
|
|
|||||||||||||
|
Erklärung |
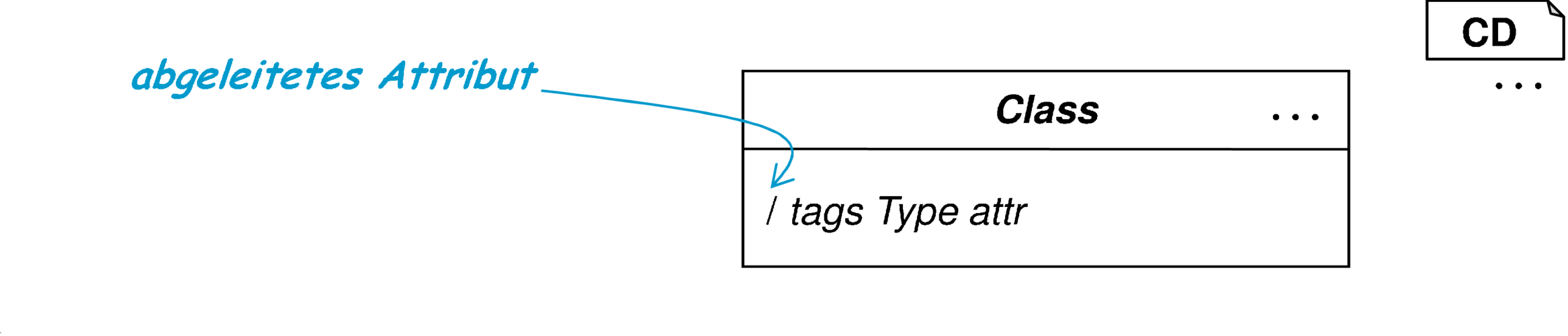
Für ein abgeleitetes Attribut /attr existiert eine Berechnungsvorschrift als OCL-Invariante der Form attr=expr oder eine Methode calcAttr. Die Häufigkeit der Änderungen der zur Berechnung verwendeten Attribute liegt in einer ähnlichen Größenordnung wie die Abfrage des abgeleiteten Attributs. Deshalb wird das abgeleitete Attribut erst bei Bedarf berechnet und nicht gespeichert. |
|||||||||||||
|
|
||||||||||||||
|
Attributdefinition |
|
|||||||||||||
|
|
|
|||||||||||||
|
|
||||||||||||||
|
Attribute |
|
|||||||||||||
|
|
||||||||||||||
|
Beachtenswert |
Vorteil gegenüber der Attribut2eager Version ist, dass der Kontrollfluss nicht invertiert wurde und damit keine bidirektionale Assoziationen oder eine andere Infrastruktur notwendig sind. Ineffizienz kann aber durch wiederholt durchgeführte Berechnung des Attributs entstehen. Zirkuläre Abhängigkeiten führen auch hier zu nichtterminierenden Neuberechnungen und sind daher verboten. |
|||||||||||||
|
|
|
|||||||||||||

Eine im Bereich der graphischen Oberflächen gelegentlich verwendete Form des Model-View-Controller-Pattern nutzt Vorteile beider Ansätze, indem die change propagation nur in einer booleschen Statusvariable vermerkt wird, aber eine Neuberechnung erst bei Bedarf erfolgt.
5.1.2 Methoden
Für die Implementierung von Methoden stehen mehrere Strategien zur Verfügung, die von der Ausgangsituation abhängig sind:
- Der Methodenrumpf ist bereits in einem anderen Artefakt formuliert und muss nur in die Methode eingesetzt werden. Dabei werden auch die notwendigen Transformationen beispielsweise von Attributzugriffen vorgenommen.
- Die Methode ist durch ein Vor-/Nachbedingungspaar beschrieben, wobei die Nachbedingung, wie in Abschnitt 4.1 diskutiert, algorithmisch formuliert ist und direkt in Code umgesetzt werden kann.
- Die Methode ist durch ein Vor-/Nachbedingungspaar beschrieben, das aber nicht algorithmisch umsetzbar und deshalb nur für Tests geeignet ist.
- Für diese Methode gibt es noch keine Implementierung oder Spezifikation.
Für jeden dieser Fälle ist eine eigenständige Vorgehensweise notwendig. Der erste Fall benötigt nur die Integration des Methodenrumpfs mit der Signatur sowie die Umsetzung zum Beispiel der Attributzugriffe im Methodenrumpf.
|
|
|
|
Methode1impl: Methoden mit gegebener Implementierung
|
|
|
|
|
|
Erklärung |
Eine Methode meth mit gegebenem Methodenrumpf code wird in Java umgesetzt. |
|
|
|
|
Methodendefinition |
|
|
|
|
|
|
|
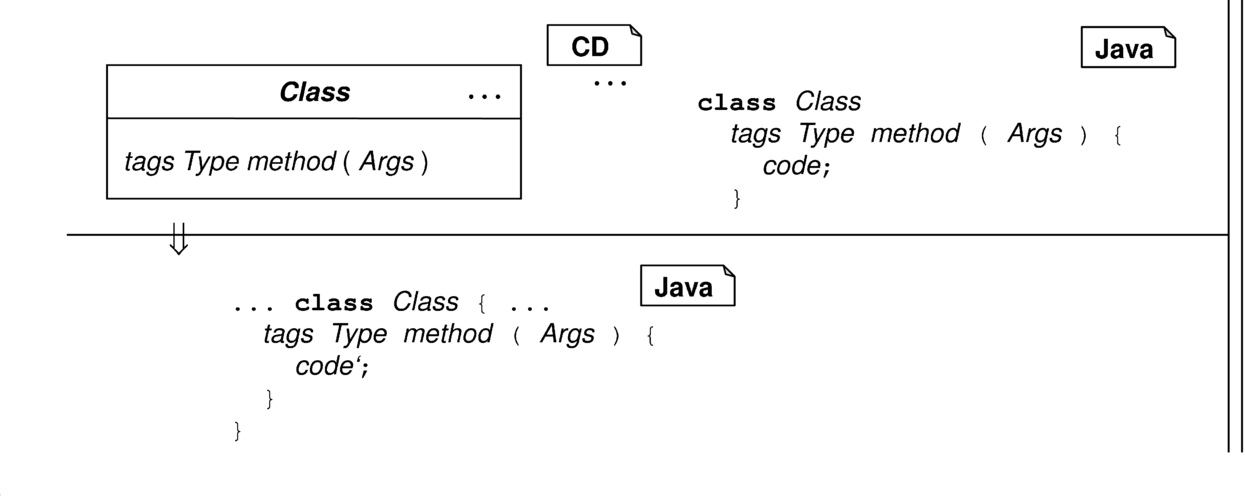
Für die Beschaffung des Methodenrumpfs gibt es in den heute verfügbaren Werkzeugen mehrere Ansätze. Eine Möglichkeit ist, den Rumpf als Textstück, zum Beispiel als Kommentar, der Methodensignatur im Diagramm zu hinterlegen und durch Anwählen zugänglich zu machen. Dies ist allerdings für große Systeme mit vielen Methoden nicht praktikabel. Die Technik des „Round Trip Engineering“ liest die Methodenrümpfe direkt aus dem Quellcode, um sie dorthin zurück zu schreiben.2
Neben oder statt Java-Implementierungen können auch OCL-Spezifikationen von Methoden in der Form von Vor- und Nachbedingungspaaren verwendet werden. In Abschnitt 3.4.3, Band 1 ist die Integration mehrerer solcher Methodenspezifikationen behandelt worden. Deshalb kann hier von einem einzelnen Paar ausgegangen werden. Ist die Spezifikation algorithmisch in der in Abschnitt 4.1.2 diskutierten Form, so kann daraus direkt Code erzeugt werden.3
Weil die Umsetzung einer derartig spezifizierten Methode im Wesentlichen auf der in Abschnitt 5.3 diskutierten Umsetzung von OCL in Java-Code beruht, soll hier auf eine explizite Formulierung der Transformationsregel verzichtet werden.
Im dritten oben genannten Fall existiert sowohl eine Implementierung als auch eine Spezifikation. Damit ist es sinnvoll, die Spezifikation zur Prüfung während der Laufzeit einzusetzen. Der Generator weiß, ob er effizienten Produktionscode oder mit diesen Prüfungen instrumentierten Code erzeugen soll. Zum Beispiel bieten Eiffel- und Java-Übersetzer die Möglichkeit, Zusicherungen optional zu übersetzen.
Im Prinzip ist nur die Vorbedingung vor Start der Methode und die Nachbedingung nach deren Ende zu testen. Dabei sind jedoch unter Umständen mit dem let-Konstrukt lokal definierte Variable und eventuell in der Nachbedingung genutzte Anfangszustände von Attributen zu sichern. Diese Sicherung kann komplex sein, wenn die benutzten Attribute in anderen Objekten liegen und die Zugangspfade ihrerseits verändert worden sein können. Eine über den Abschnitt 3.4.3, Band 1 hinausgehende ausführliche Diskussion dieser Problematik ist zum Beispiel in [RG02] zu finden.
Als letzte Variante soll hier noch der Fall kurz diskutiert werden, in dem es weder eine Implementierung noch eine algorithmisch ausführbare Spezifikation für eine Methode gibt. Dann kann die Methode nicht automatisiert implementiert werden. Für Simulationen und Tests, die diese Methode vielleicht nur marginal berühren, sind jedoch Strategien möglich und sinnvoll, Dummy-Implementierungen zu generieren.
- Spielt die Methode bei den durchzuführenden Tests keine Rolle, so kann ein Fehleraufruf oder die Rückgabe eines Default-Werts in die Methode generiert werden.
- Ist die Methode noch nicht realisiert, so kann ein interaktives Eingabefeld während Simulationsläufen dazu benutzt werden, dass der Nutzer auf Basis der aktuellen Parameter jeweils selbst das Ergebnis bestimmt.
- Für eine, endliche Menge von Eingaben können in einer Tabelle Ergebnisse abgelegt sein. Diese Ergebnisse können zum Beispiel aus früheren interaktiven Simulationsläufen mitprotokolliert worden sein.
Einerseits ist eine interaktive Eingabe von Ergebnissen einzelner Methoden für automatisierte Testläufe nicht sinnvoll, andererseits können damit während der Vorführung eines Prototypen sofort Anwenderentscheidungen in das System zurückgeführt werden. Diese können protokolliert und später zum Beispiel als Testdaten genutzt werden. Diese interaktive Form des Erkenntnisgewinns ist sicherlich beschränkt, kann aber unter Umständen zu effektiverer Kommunikation mit Anwendern führen.
In der UML/P ist es nicht üblich, Hilfsmethoden wie getAttr in Klassendiagrammen explizit zu vermerken. Dadurch bleibt das Modell kompakter und übersichtlicher. Auch müssen diese Funktionen in Coderümpfen, die bei der Generierung übersetzt werden, nicht explizit verwendet werden. Es reicht aus, den Attributzugriff und die Attributbesetzung in Form von Zuweisungen einzusetzen. Ein Codegenerator übersetzt diese wie in den Transformationsregeln beschrieben in Methodenaufrufe. Es sollte jedoch erlaubt sein, diese Methoden direkt zu verwenden. Außerdem ist unter Umständen sinnvoll, die Generierung einer solchen Methode vorwegzunehmen, indem eine manuelle Implementierung angegeben wird. Dadurch lassen sich eventuell Optimierungen vornehmen oder zusätzliche Funktionalitäten realisieren.
5.1.3 Assoziationen
Eine unidirektionale Assoziation wird standardmäßig durch ein Attribut umgesetzt. Der Rollenname wird dabei als Attributname verwendet. Fehlt der notwendige Rollenname, so wird wie bei den in Abschnitt 3.3.8, Band 1 angegebenen Navigationsregeln ein Attributname aus dem Assoziationsnamen oder dem Namen der gegenüberliegenden Klasse gebildet.
Kardinalitäten werden entsprechend berücksichtigt: „0..1“ führt zu einem einfachen Attribut, das den Wert null annehmen darf, „1“ führt zu einem einfachen Attribut, das immer besetzt ist, und eine Assoziation mit Kardinalität „⋆“ wird mengenwertig. Abhängig von zusätzlichen Merkmalen wie {ordered} stehen Mengen- oder Listen-Implementierungen zur Auswahl. Für qualifizierte Assoziationen wird entsprechend eine Abbildung (Map) zur Verfügung gestellt.
Bidirektionale Assoziationen werden durch Attribute auf beiden Seiten realisiert, die durch ein geeignetes Methodenprotokoll konsistent gehalten werden. Ist keine Navigationsrichtung angegeben, so wird eine geeignete Navigationsrichtung aus dem Kontext ermittelt und gegebenenfalls werden beide Richtungen realisiert.
Um die oben genannte Konsistenz bidirektionaler Assoziationen zu sichern, werden alle Zugriffe auf die Assoziation über generierte Methoden geführt. Die Form dieser generierten Methoden, also das für eine Assoziation verwendbare API, hängt von den Eigenschaften und Merkmalen der Assoziation ab.
So werden bei den Merkmalen {addOnly} und {frozen} entsprechende Funktionen zur Modifikation eingeschränkt. Abgeleitete Assoziationen werden mit denselben Prinzipien behandelt, wie abgeleitete Attribute. Das heißt, es werden nur Abfragemethoden zur Verfügung gestellt und diese durch Berechnungen implementiert.
Nachfolgende Transformation ist exemplarisch für bidirektionale, in beiden Richtungen mit Kardinalität „⋆“ versehene Assoziationen.
|
|
|
||||||||||||||||||||
|
Assoziation*,*,bidir: Bidirektionale Assoziation
|
|||||||||||||||||||||
|
|
|
||||||||||||||||||||
|
Erklärung |
Assoziationen werden in den Zustandsraum zumindest einer der beteiligten Klassen transformiert, indem entsprechende Attribute und Zugriffsfunktionen generiert werden. Diese Transformationsregel ist für bidirektionale Assoziationen mit Kardinalität „⋆“ in beiden Richtungen geeignet. Die Assoziation ist nicht abgeleitet und keine Komposition. |
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
Definition der Assoziation |
|
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
Zugriffsfunktionen |
etc.
|
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
Modifikation |
etc.
|
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
OCL- Navigation |
|
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
Zusätzliche Methoden |
|
||||||||||||||||||||
|
|
|||||||||||||||||||||
|
Beachtenswert |
Die durch ein Protokoll gesicherte Konsistenz zwischen beiden Enden einer bidirektionalen Assoziation besitzt im Normalfall nur konstanten Zusatzaufwand, ist also vertretbar. Ist eine Assoziation nur unidirektional, so kann dieser Aufwand dennoch wegfallen. |
||||||||||||||||||||
|
|
|
||||||||||||||||||||
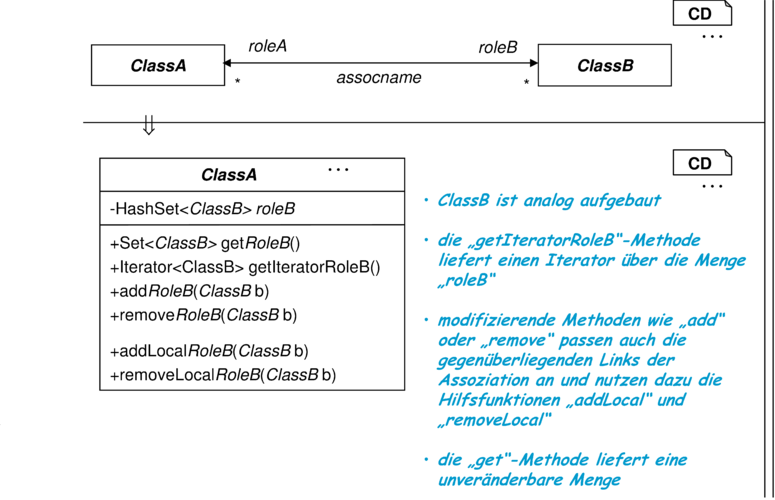

Die Umsetzung von Assoziationen in Java-Code zeigt, wie groß die Variationsmöglichkeiten bei der Codegenerierung sind. Variabel abhängig von den Eigenschaften der Assoziation ist nicht nur das API einer Assoziation (also welche Funktionen in UML/P zum Zugriff und zur Manipulation zur Verfügung stehen), sondern auch die intern genutzte Datenstruktur. Da die Wahl der Datenstruktur zumindest Auswirkungen auf das Laufzeitverhalten der Implementierung hat, wird sinnvollerweise durch geeignete Steuerungsmechanismen wie etwa dem Merkmal {HashMap} oder durch geeignete Anpassung der Skripte die Auswahl der Implementierung ermöglicht.
Für Assoziationen mit beschränkten Kardinalitäten ist außerdem zu klären, wie der Versuch einer Verletzung der Kardinalität behandelt wird. Dafür gibt es zum Beispiel die Varianten, dies robust zuzulassen, aber gegebenenfalls eine Warnung zu protokollieren, bis hin zur Erzeugung einer Exception, die dann vom aufrufenden Objekt zu behandeln ist.
Neben der oben vorgeschlagenen Form der Implementierung einer Assoziation gibt es Vorschläge, die Links durch eigenständige Objekte zu realisieren oder durch eine global verwaltete Datenstruktur zu ersetzen. All diese Erweiterungen haben als Ziel, zusätzliche Funktionalität anzubieten, die durch das API der Modellierung zugänglich werden, oder Verhaltens- beziehungsweise Sicherheitseigenschaften zu optimieren. Eine globale statische Datenstruktur in Form einer Abbildung von Quell- zu Zielobjekt ist zum Beispiel von Interesse, wenn die Assoziation sehr dünn besetzt ist und der Speicherplatz dadurch effizienter genutzt wird. Dies sollte dem Nutzer der API verborgen bleiben, da es sich um Realisierungsdetails handelt.
Die notwendige Umsetzung von Java-Code zur Sicherung der Konsistenz der Assoziation zeigt, dass es wichtig ist, dass der Codegenerator die vollständige Kontrolle über alle Teile des generierten Codes, also auch über Methodenrümpfe hat. Dadurch wird beispielsweise die für bidirektionale Assoziationen gültige Konsistenzbedingung gesichert:
OCL  context ClassA a, ClassB b inv: context ClassA a, ClassB b inv: |
| a.roleB.contains(b) <=> b.roleA.contains(a) |
Verfahren des Roundtrip-Engineering können dies nicht leisten, da es dem Entwickler die Möglichkeit gibt, beliebig in generierte Datenstrukturen einzugreifen. Dort müsste also diese Konsistenzbedingung zur Laufzeit geprüft werden. Bei einer Transformation der Methodenrümpfe durch den Codegenerator können die Zugriffe und Modifikationen für die Assoziation überprüft beziehungsweise transformiert und damit verhindert werden, dass dem Entwickler die Methode addLocalRoleB zur Programmierung zur Verfügung steht.6
5.1.4 Qualifizierte Assoziation
Die qualifizierte Assoziation bietet gegenüber der normalen Assoziation ein angepasstes API, das die qualifizierte Selektion und Manipulation erlaubt, aber auch einige Operationen zur Modifikation unqualifizierter Assoziationen verbietet. Deshalb wird für die qualifizierte Assoziation eine eigene Transformationsliste angegeben, die auch das API beschreibt.
|
|
|
|||||||||||||||||||||||||||||||||||
|
Assoziationquali: Qualifizierte Assoziation
|
||||||||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||||||
|
Erklärung |
Eine qualifizierte Assoziation wird ähnlich der normalen Assoziation umgesetzt, bietet aber angepasste Funktionalität für qualifizierten Zugriff. Diese Transformationsregel ist geeignet für unidirektionale qualifizierte Assoziationen mit Kardinalität „1“.7 Die Assoziation ist weder abgeleitet noch eine Komposition. |
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Definiten der Assoziation |
|
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Zugriffsfunktionen |
|
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Modifikation |
|
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
OCL- Navigation |
|
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Zusätzliche Methoden |
|
|||||||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||
|
Beachtenswert |
Abhängig vom Zweck des Codes (Test, Simulation, Produktion) werden verschiedene Strategien für die Behandlung des Fehlerfalls von einer Fehlermeldung über eine Mitteilung in einem Protokoll bis hin zur robusten Implementierung eingesetzt. Der Zugriff auf das hier verwendete Attribut roleB ist entsprechend der für dieses Attribut gültigen Transformation ebenfalls umzusetzen. |
|||||||||||||||||||||||||||||||||||
|
|
|
|||||||||||||||||||||||||||||||||||
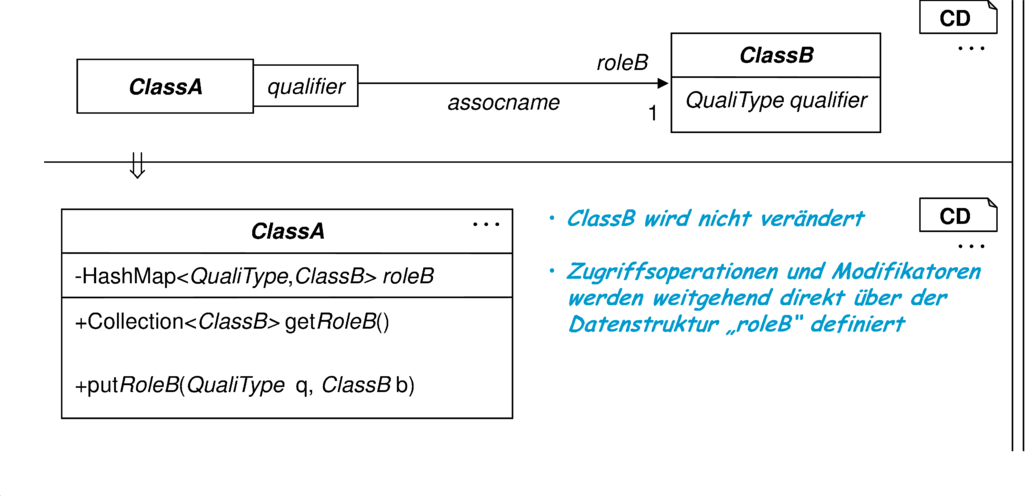

Die Transformation der qualifizierten Assoziation nutzt die Komponierbarkeit von Transformationsregeln, da hier zunächst eine Assoziation in ein Attribut transformiert wird, das durch eine weitere Transformation durch Zugriffsmethoden gekapselt wird. Bei dieser Kapselung durch Zugriffsmethoden ist allerdings zu beachten, dass die Methode getroleB zwei unterschiedliche Aufgaben zu erfüllen hat. Bei qualifizierten Assoziationen ist zwischen (1) der Menge aller durch die Links erreichbaren Objekte und dem (2) Attributinhalt zu unterscheiden. Nur bei normalen Assoziationen sind beide Bedeutungsvarianten identisch. Die Methode getroleB realisiert Variante (1). Für die Variante (2) wird bei Bedarf eine Methode mit dem Namen getroleBAttribute eingeführt, die hier ein Map-Objekt zurückgibt. Durch die zahlreichen qualifizierten Zugriffsmöglichkeiten sollte jedoch der Zugriff auf die realisierende Map-Datenstruktur durch den Modellierer nicht notwendig sein.
5.1.5 Komposition
Wie bereits in Abschnitt 2.3.4, Band 1 diskutiert, besteht zwischen den Lebenszyklen des Kompositums und den davon abhängigen Objekten eine zeitliche Beziehung. Diese ist jedoch durch erhebliche Interpretationsunterschiede gekennzeichnet. Die Komposition wird strukturell wie eine normale Assoziation behandelt, das Anlegen beziehungsweise Entfernen von Links aus einer Komposition unterliegt aber der jeweiligen Interpretation. Entsprechend werden einige Operationen des Assoziations-API nicht angeboten oder unterliegen Restriktionen.
Eine Interpretation des Kompositums, die relativ verbreitet ist und im Auktionsprojekt als einzige verwendet wurde, wird nachfolgend dargestellt.
|
|
|
|||||
|
Kompositionfrozen: Fixierte Komposition
|
||||||
|
|
|
|||||
|
Erklärung |
Die fixierte Form der Komposition wird genutzt, wenn das abhängige Objekt dieselbe Lebensspanne wie das Kompositum hat, während der Initialisierungsphase des Kompositums erzeugt wird und der Link zwischen beiden Objekten unveränderbar ist. Diese Transformationsregel ist geeignet für die unidirektionale Kompositionen mit Kardinalität „1“. |
|||||
|
|
||||||
|
Kompositionsdefinition |
|
|||||
|
|
|
|||||
|
|
||||||
|
Zugriffsfunktion |
|
|||||
|
|
||||||
|
Modifikation |
Die Besetzung des Attributs roleB darf ausschließlich im Konstruktor, also der Initialisierungsphase erfolgen.8 Dafür wird entweder eine Factory oder ein new-Kommando eingesetzt: |
|||||
|
|
|
|||||
|
|
||||||
|
OCL- Navigation |
wie in vorangegangenen Transformationsregeln |
|||||
|
|
||||||
|
Beachtenswert |
Die Restriktion, dass das abhängige Objekt erst im Konstruktor des Kompositums erzeugt wird, stellt sicher, dass abhängige Objekte nicht mehrfach verwendet werden.9 Eine weniger strikte Umsetzung würde zum Beispiel erlauben, das abhängige Objekt bereits als Parameter an den Konstruktor zu übergeben. Dann kann jedoch nicht mehr sicher festgestellt werden, ob das Objekt neu erzeugt wurde und damit der Kompositionsbeziehung genügt. |
|||||
|
|
|
|||||
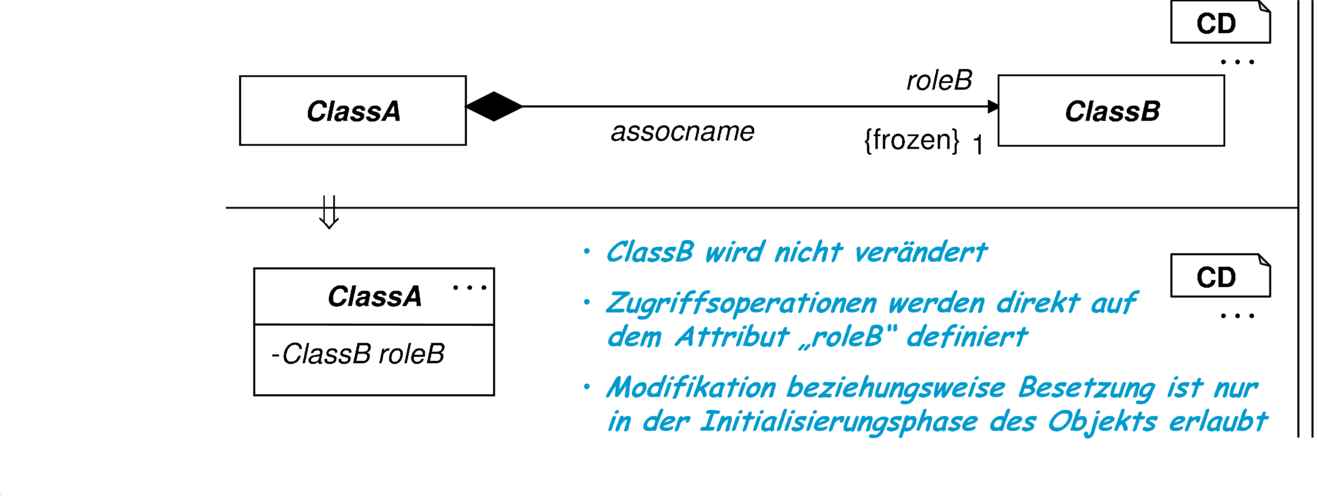
5.1.6 Klassen
Die Übersetzung einer Klasse mit ihren Attributen, Methoden, Assoziationen, Kompositionen und den bislang noch nicht besprochenen Vererbungsbeziehungen ist relativ schematisch, da die kanonische Vorgehensweise die direkte Abbildung der UML-Klasse in die Java-Klasse ist. Die Umsetzung von Klassen ist jedoch stark getrieben durch Stereotypen und Merkmale, die steuern, welche zusätzliche Funktionalität und welche Varianten der Transformation von Attributen vorgenommen werden. In dieser Grundtransformation werden keine Stereotypen berücksichtigt.
|
|
|
|||||||||||||
|
Klassen: Umsetzung einer Klasse
|
||||||||||||||
|
|
|
|||||||||||||
|
Erklärung |
Eine Klasse wird direkt übernommen. In Abhängigkeit der ihr beigefügten Stereotypen und Merkmale sowie genereller Übersetzungsvorgaben wird für die Klasse zusätzliche Funktionalität generiert, die dem Entwickler bei der Benutzung der Klasse zur Verfügung steht. |
|||||||||||||
|
|
||||||||||||||
|
Klassendefinition |
|
|||||||||||||
|
|
|
|||||||||||||
|
|
||||||||||||||
|
Vergleichsfunktion |
|
|||||||||||||
|
|
|
|||||||||||||
|
|
||||||||||||||
|
Hashfunktion |
|
|||||||||||||
|
|
||||||||||||||
|
|
||||||||||||||
|
Stringumwandlung |
|
|||||||||||||
|
|
||||||||||||||
|
Konstruktoren |
|
|||||||||||||
|
|
|
|||||||||||||
|
|
||||||||||||||
|
Protokollausgabe |
|
|||||||||||||
|
|
|
|||||||||||||
|
|
||||||||||||||
|
Beachtenswert |
Neben stringForProtocol gibt es eine Reihe weiterer Funktionen, die in entsprechender Form realisiert werden, aber hier nicht erwähnt wurden. Einige sind aus der von allen Objekten abgeleiteten Klasse Object (beispielsweise clone), andere folgen aus Interfaces, die zu implementieren sind (beispielsweise compareTo aus dem Interface Comparable) und wieder andere sind bedingt durch Implementierungsvorgaben für den Codegenerator. Dazu gehören Funktionalitäten für die Protokollausgabe wie oben beschrieben, Speicherung, Fehlerbehandlung und zusätzliche Funktionen, die zur Bearbeitung von Tests hilfreich sind. |
|||||||||||||
|
|
|
|||||||||||||
|
Tabelle 5.7.: Klassen: Umsetzung einer Klasse
|
||||||||||||||
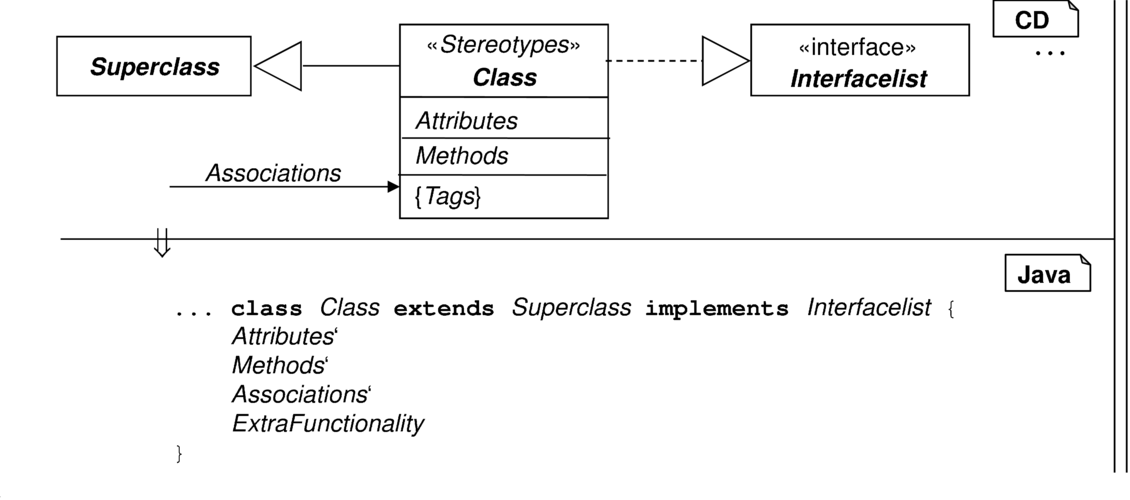





Gerade für den Einsatz in Testumgebungen sind unter Umständen eine Reihe weiterer Methoden und Datenstrukturen für eine Klasse zu generieren. Bei der Generierung solcher uniformen Methoden für Implementierung und Tests kann ein Codegenerator wertvolle Dienste leisten.
Eine der wenigen und eher selten gewählten Alternativen zu der hier beschriebenen Abbildung sei dennoch erwähnt. Sie verzichtet darauf, das Typsystem der Zielsprache Java zu nutzen und legt stattdessen Attribute als Abbildung des Attributnamens auf den Wert mit dem HashMap (String, Object) ab. Es ist dann im Prinzip ausreichend, eine einzige Java-Klasse in der in Abbildung 5.8 dargestellten Form zu realisieren, die zwar einiges an zusätzlicher Flexibilität mit sich bringt, aber ineffizienter ist. Eine ähnliche Form wird zum Beispiel zur Ressourcen-Verwaltung von Parametern verwendet.
 class Chameleon { ...
class Chameleon { ...
| // Träger aller Attribute |
| HashMap(String,Object) attributes; |
| public Object get(String attributeName) { |
| return attributes.get(attributeName); |
| } |
| // Typprüfung: feststellen, ob bestimmte Attribute vorhanden sind |
| public boolean isInstanceOf(Set<String> attributeNames) { |
| return attributes.keySet().containsAll(attributeNames); |
| } |
| } |
5.1.7 Objekterzeugung
Ein letzter interessanter Punkt im Kontext der Codeerzeugung für Klassen ist das Management ihrer Objekte. Dazu gehört beispielsweise die Erzeugung von Objekten, die Verwaltung und der effiziente Zugriff auf einzelne Objekte oder das Speichern und Laden von Datenbanken. Verwaltungstätigkeiten werden oft so genannten „Management-Objekten“ auferlegt, die neben einer Sammlung der im Speicher befindlichen Objekte die transaktionsgesteuerte Abbildung auf die Datenbank und den effizienten Zugriff geladener Objekte erlauben. Von all diesen Tätigkeiten soll nachfolgend nur die Objekterzeugung in Java diskutiert werden, da sie unter anderem für Tests instrumentierbar sein muss.
Die in den Coderümpfen verwendete Form des new Class(...) kann bei der Codeerzeugung durch den Aufruf geeigneter Factory-Methoden umgesetzt werden. Dies erhöht die Flexibilität bei der Codeerzeugung beträchtlich, da so Unterklassen verwendet oder in automatisierten Tests Dummies eingesetzt werden können.10
|
|
|
||||||||||||||||||||||
|
Objekterzeugung: Objekte mit einer Factory erzeugen
|
|||||||||||||||||||||||
|
|
|
||||||||||||||||||||||
|
Erklärung |
Im Quellcode wird die Objekterzeugung mit dem new-Konstrukt vorgenommen. Der generierte Code enthält stattdessen Factory-Aufrufe. Eine Standard-Factory wird generiert und kann durch Bildung von Unterklassen auf spezifische Situationen angepasst werden. |
||||||||||||||||||||||
|
|
|||||||||||||||||||||||
|
Objekterzeugung |
|
||||||||||||||||||||||
|
|
|||||||||||||||||||||||
|
Klasse Factory |
|
||||||||||||||||||||||
|
|
|
||||||||||||||||||||||
|
|
|||||||||||||||||||||||
|
Alternative |
Es ist unter anderem möglich, statt einem einzelnen Attribut f für mehrere Gruppen von zu erzeugenden Klassen beziehungsweise sogar für jede Klasse ein eigenes Attribut einzusetzen, so dass die Generierung von Objekten individuell angepasst werden kann: |
||||||||||||||||||||||
|
|
wobei Aufrufe wieder so transformiert werden:
|
||||||||||||||||||||||
|
|
|
||||||||||||||||||||||
|
Tabelle 5.9.: Objekterzeugung: Objekte mit einer Factory erzeugen
|
|||||||||||||||||||||||


Mehrstufige Übersetzung
Die exemplarisch diskutierten Varianten zur Umsetzung von Klassendiagrammen zeigen die hohe Bandbreite an möglichen Generierungsformen. Wie bereits diskutiert folgt daraus, dass die Codegenerierung eine grosse Flexibilität benötigt, um die jeweils notwendigen Aufgaben zu erfüllen. Ein Weg, die Flexibilität zu steigern, ist die Möglichkeit, aus mehreren Templates oder Skripten auszuwählen. Darüber hinaus nutzen sich die Templates gegenseitig, indem zum Beispiel Assoziationen zunächst in Attribute transformiert und diese dann durch Zugriffsmethoden gekapselt werden. Die in diesem Abschnitt gezeigten Regeln zur Transformation von Konzepten der Klassendiagramme in Java-Code sind daher nicht unabhängig voneinander. Abbildung 5.10 zeigt die Abhängigkeiten der Transformationsregeln.
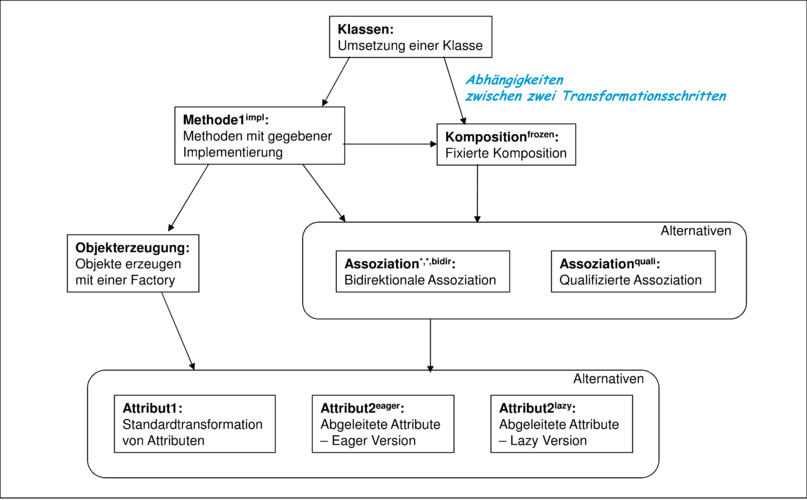
Dabei sind nur die explizit definierten Regeln beschrieben, aber es sollte für ein geeignetes Framework weitere Transformationsregeln geben, die durch weitere Templates festgelegt werden. Die Auswahl der Alternativen ist manchmal durch den Kontext oder Eigenschaften des übersetzen Konzepts vorgegeben (wie hier zum Beispiel bei den Assoziationen) oder kann durch Einstellungen des Generators gesteuert werden (wie zum Beispiel bei den abgeleiteten Attributen).
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |