Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Agile und UML-basierte Methodik
3 Kompakte Übersicht zur UML/P
4 Prinzipien der Codegenerierung
4.1 Konzepte der Codegenerierung
4.2 Techniken der Codegenerierung
4.3 Semantik der Codegenerierung
4.4 Flexible Parametrisierung eines Codegenerators
5 Transformationen für die Codegenerierung
6 Grundlagen des Testens
7 Modellbasierte Tests
8 Testmuster im Einsatz
9 Refactoring als Modelltransformation
10 Refactoring von Modellen
11 Zusammenfassung und Ausblick
Literatur
| << zurück | MBSE Home | weiter >> |
4.1 Konzepte der Codegenerierung
In Vorwegnahme der nachfolgend diskutierten konzeptionellen Grundlagen werden in Abbildung 4.1 die wesentlichen Begriffe einführend definiert.
Der Einsatz eines Codegenerators hat einige Vorteile gegenüber konventioneller Programmierung. Die Verständlichkeit der benutzten Modellierungs- beziehungsweise Programmiersprache wird erhöht, indem die Sprache kompakter und/oder durch graphische Elemente übersichtlicher wird. Die Effizienz der Softwareentwicklung wird erhöht. Allein dadurch, dass weniger Code manuell zu schreiben, prüfen und testen ist, können Entwickler ihre Effizienz steigern. Zusätzliche Aspekte, wie die bessere Wiederverwendbarkeit von abstrakten Modellen aus einer Modellbibliothek, steigern die Entwicklereffizienz weiter. Dies führt zu einer Reduktion des Gesamtaufwands für die Softwareentwicklung. Dadurch wird weniger Projektorganisation notwendig, wodurch weitere Effizienzsteigerungen möglich werden.
Die Wiederverwendbarkeit ist dabei auf mehreren Ebenen möglich. Ein Modell kann in angepasster Form in einem ähnlichen Projekt oder einer Produktlinie [BKPS04] wiederverwendet werden. Idealerweise kann durch wiederholte Verbesserung ein Modell-Framework entstehen, das für gleichartige Projekte direkt verwendbar ist und sogar einen speziell dafür geeigneten Codegenerator besitzt. Das im Codegenerator eingebettete technische Wissen beispielsweise zur Erzeugung von Schnittstellen oder sicherer und effizienter Übertragungsmechanismen kann unabhängig davon wiederverwendet werden. Eine weitere Möglichkeit zur Wiederverwendung von Modellen ergibt sich innerhalb eines Projekts. Ein Objektdiagramm kann zum Beispiel sowohl als Prädikat als auch konstruktiv zur Erzeugung einer Objektstruktur eingesetzt werden. Beide Formen können außerdem im Produktionssystem oder bei der Testfalldefinition eingesetzt werden. Der dafür generierte Code ist, wie in Abschnitt 5.2 noch diskutiert, sehr unterschiedlich und daher manuell viel aufwändiger zu erstellen.
Gelegentlich sind Codegeneratoren heute auch bereits in der Lage, effizienteren Code zu erstellen, als dies in vertretbarem Aufwand durch manuelle Optimierungen möglich wäre. Dies gilt natürlich vor allem für ausgereifte Compiler normaler Programmiersprachen, die eine Reihe von Optimierungstechniken einsetzen. Für ausführbare Modellierungssprachen wie die UML/P ist davon auszugehen, dass die Steigerung der Effizienz der Entwickler derzeit durch eine weniger effiziente Implementierung erkauft werden muss. Entsprechend ist der Einsatz von Generatoren für Modellierungssprachen vor allem bei Individualsoftware und erst in zweiter Linie bei eingebetteter, massenhaft in möglichst kostengünstigen Geräten vertriebener Systemsoftware sinnvoll.
Die flexible Generierung von Code aus fachlichen Modellen erlaubt letztendlich auch die Behandlung von technischen und teilweise fachlichen Variabilitäten im Sinne von [HP02]. Dabei werden offene technische Aspekte des funktionalen Modells durch einen jeweils technologiespezifisch angepassten Generator geeignet ausgefüllt.
4.1.1 Konstruktive Interpretation von Modellen
Wie bereits in Band 1 beschrieben, ist ein Modell seinem Wesen nach eine in Maßstab, Detailliertheit oder Funktionalität verkürzte beziehungsweise abstrahierte Darstellung des originalen Systems [Sta73]. Modelle werden immer dort eingesetzt, wo das tatsächliche System so komplex ist, dass es sich zunächst lohnt, bestimmte Eigenschaften des Systems am Modell zu analysieren oder dem Kunden zu erklären. Dazu gehören Architekturmodelle von Gebäuden ebenso wie technische Modelle komplexer Maschinen oder Modelle sozialer und wirtschaftlicher Zusammenhänge. Bei manchen Modellen, wie zum Beispiel Bauplänen oder Schaltzeichnungen, steht der Wunsch nach einer Beschreibung des Aufbaus (Architektur) im Vordergrund, bei anderen die Simulation von Funktionalität und anderer verhaltensorientierter Eigenschaften.4
Generell gilt aber, dass diese Modelle und Bauzeichnungen als Hilfsmittel für die spätere Erstellung des Artefakts dienen. Wird das Modell erstellt, um danach das eigentliche Artefakt zu bilden, so hat das Modell eine vorschreibende (präskriptive) Wirkung. Im Gegensatz dazu wird ein Modell beschreibend (deskriptiv) eingesetzt, wenn das Original vor dem Modell existiert. Beispiele hierzu sind etwa eine Modelleisenbahn oder Fotografien [Lud02].
Aufgrund der Immaterialität von Software entfalten Modelle in der Softwareentwicklung zusätzlich zur deskriptiven Wirkung auch eine konstruktive Wirkung. Wenn für die Generierung lauffähiger Software aus einem immateriellen, im Computer gespeicherten Modell nur ein Knopfdruck notwendig ist, dann wirkt das Modell als konstruktive Vorgabe. Der Quellcode einer Programmiersprache kann aufgrund der automatisierten Übersetzung als zu dem erzeugten Objektcode äquivalent angesehen werden. Streng genommen sind Quellcode und Objectcode ebenfalls Modelle des Systems. Für praktische Belange werden sie jedoch – und mit Recht vereinfachend – mit dem System selbst identifiziert. Dieselbe Annahme kann auch für ausführbare UML/P-Modelle getroffen werden.
Die konstruktive Verwendung der Modelle hat einige Auswirkungen, die bei einem nicht-konstruktiven Einsatz nicht auftreten. Zum Beispiel verändert die Hinzunahme oder das Weglassen von Elementen des Modells sofort das modellierte System. Ein Beispiel ist die Verwendung mehrerer Statecharts zur Modellierung des Verhaltens einer Klasse auf verschiedenen Abstraktionsstufen. Ein Generator, der damit umgehen kann, simuliert diese parallel und realisiert damit ein mehrdimensionales Zustandskonzept5 für eine Klasse.6 Wird nun ein weiteres Statechart als Modell hinzugenommen, das ausschließlich bereits vorhandene Information in abstrakterer Form darstellt, so wird das Zustandskonzept weiter aufgebläht. Das ändert zwar nicht das funktionale Gesamtverhalten, wohl aber die interne Struktur und das Zeitverhalten des Systems.
Modelle werden also in der Softwareentwicklung in verschiedenen Rollen eingesetzt. Dazu gehören die automatisierte Generierung von Produktionscode, aber auch von Tests. Die manuelle Umsetzung eines Modells ist ebenso möglich, wie die Erstellung von Modellen, nachdem das Artefakt bereits existiert. Abbildung 4.2 charakterisiert die drei Dimensionen zur Unterscheidung des Einsatzes von Modellen.
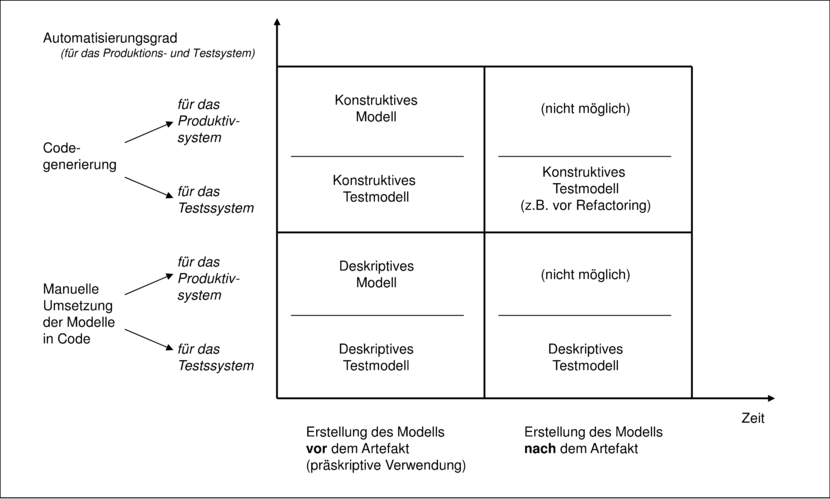
Streng genommen ist die Erstellung eines konstruktiv verwendeten Modells nach dem Artefakt möglich und zum Beispiel im Reverse Engineering sinnvoll. Jedoch wird dieses Modell nicht zur Erstellung des bereits vorhandenen Originals, sondern für die nächste Version verwendet.
Der Unterschied zwischen der konstruktiven und der deskriptiven Interpretation von Modellen ist verwandt zu einem ähnlichen Phänomen, das bei algebraischen Spezifikationssprachen detailliert diskutiert wurde. Einem deskriptiv eingesetzten Modell sollte eine lose Semantik [BFG+93] zugeordnet sein. Das heißt, dass verschiedene Implementierungen beschrieben werden können, die das Modell erfüllen. Viele dieser Implementierungen enthalten beispielsweise weitere Zustandskomponenten, Funktionalität oder Schnittstellen, die im vorliegenden, unvollständigen Modell nicht explizit erwähnt sind. Ein Klassendiagramm beschreibt dann einen Ausschnitt eines Systems, da noch weitere, ungenannte Klassen besitzen kann. Ein deskriptives Modell kann daher unvollständig sein. In Band 1 [Rum11] wurde beispielsweise eine lose Semantik für Sequenzdiagramme beschrieben.
Demgegenüber stellt ein konstruktiv eingesetztes Modell eine vollständige Beschreibung des Softwaresystems dar, da allein aus dem Modell das gesamte lauffähige System generiert wird. Dies entspricht bei algebraischen Spezifikationen einer initialen Semantik, die einem Modell genau eine Implementierung zuordnet.7 8
4.1.2 Tests versus Implementierung
Die UML/P erlaubt die Erstellung von Modellen, die sich sowohl zur Testgenerierung als auch zur Generierung für das Produktionssystem eignen. Dazu zählen Objektdiagramme, die, wie in Abschnitt 4.4, Band 1 besprochen, als Vorbedingungen konstruktiv eingesetzt werden, um die Ausgangssituation eines Tests herzustellen, und als Nachbedingungen eingesetzt werden, um zu beschreiben, welche Situation nach Anwendung der Funktion für einen Testerfolg erfüllt sein muss.
Aus bestimmten Teilen eines Modells lässt sich auch kein konstruktiver Code, sondern nur Testcode generieren. Beispielsweise sind OCL-Bedingungen im Allgemeinen ausführbar. Wie in Abschnitt 3.3.10, Band 1 beschrieben, gilt dies meist auch bei Benutzung von Quantoren, da mit Ausnahme der Quantoren über Grunddatentypen wie int und mengen- beziehungsweise listenwertigen Typen höheren Grades alle Quantoren endlich und damit auswertbar sind.
Dennoch ist es ein wesentlicher Unterschied, ob eine in OCL formulierte Nachbedingung nur getestet oder sogar konstruktiv erzwungen werden kann. Nahezu alle praktisch interessanten OCL-Bedingungen fallen in die erste Kategorie. Die Kategorie der konstruktiven OCL-Bedingungen ist allerdings deutlich kleiner. Das demonstrieren die folgenden zwei Beispiele.
Sortieren
Die Methode sort soll ein Array von Zahlen (int) sortieren. Eine öfter zu findende Beschreibung in Form einer Vor-/Nachbedingung ist die Folgende:
OCL  context int[] sort(int a[]) context int[] sort(int a[]) |
| pre: true |
| post: forall int i in {1..result.length-1}: |
| result[i-1] <= result[i] |
Diese Spezifikation kann sehr einfach und in linearer Zeit getestet werden. Als konstruktive Beschreibung ist sie allerdings nicht geeignet, weil ein Generator daraus keinen Sortieralgorithmus erzeugen kann. Darüber hinaus ist sie in wesentlichen Eigenschaften unvollständig, da sie nicht sichert, dass die Ausgangselemente der Reihung a[] in der Ergebnisreihung result[] wieder vorkommen müssen. Tatsächlich wäre daher eine Implementierung der Form result=new int[0] ebenfalls korrekt.
Die konstruktive Beschreibung für einen Sortieralgorithmus ist zwar im Prinzip möglich, aber genauso komplex wie eine direkte Implementierung. Gerade bei komplexen Algorithmen zeigt sich der wesentliche Vorteil deskriptiver Beschreibungen, da sie keine Implementierungsform vorwegnehmen. Sie sind daher insbesondere gegenüber effizienten Implementierungen sehr viel leichter verständlich.
Gleichungen als Zuweisungen
Zuweisungsmethoden haben im Allgemeinen die einzige Aufgabe, das möglicherweise gekapselte Attribut zu setzen:
OCL  context void setAttr(Type val) context void setAttr(Type val) |
| pre: true |
| post: attr==val |
Diese Spezifikation ist sowohl für Tests der Methode setAttr als auch für eine konstruktive Umsetzung in eine Implementierung geeignet. Wird nämlich der Gleichheitsoperator == durch den Java-Zuweisungsoperator = ersetzt, so kann die Nachbedingung als Implementierung verwendet werden. Diese Implementierung ist allerdings nur dann wirklich korrekt, wenn keine weiteren Invarianten existieren, die eine zusätzliche Veränderung anderer Attribute erforderlich machen.
Leider ist die konstruktive Umsetzung von Nachbedingungen nur unter bestimmten, sehr eng umrissenen Rahmenbedingungen möglich. Typischerweise darf eine Nachbedingung nur aus einer Konjunktion von Zuweisungen an lokale Variablen bestehen und spätere Zuweisungen dürfen die früheren nicht wieder invalidieren. Beispielsweise ist val==attr zur obigen Nachbedingung äquivalent, kann aber in dieser Form nicht in Code umgesetzt werden.9 Auch die nachfolgende Bedingung ist für eine Codegenerierung ungeeignet, da sie zyklische Abhängigkeiten enthält:
OCL  context void method(Type val) context void method(Type val) |
| pre: true |
| post: a==b+1 && b==2⋆a-val |
Für ihre konstruktive Umsetzung ist zunächst das lineare Gleichungssystem zu lösen und es kann konstruktiv formuliert werden:
OCL  context void method(Type val) context void method(Type val) |
| pre: true |
| post: a==val-1 && b==val-2 |
Natürlich gibt es eine Reihe trickreicher Verfahren zur konstruktiven Interpretation von Bedingungen, die für verschiedene Hochsprachen entwickelt wurden. Von denen seien insbesondere die Horn-Klausel-Logik von Prolog [Llo87], die Auswertung von in Gleichungslogik formulierter algebraischer Spezifikationen [EM85] und deren Erweiterung um Konditionale erwähnt. Beispielsweise kann auch die folgende Spezifikation konstruktiv umgesetzt werden:
OCL  context int abs(int val) context int abs(int val) |
| pre: true |
| post: if (val>=0) then result==val else result==-val |
Arten der Generierung
Da die Notationen der UML/P zur Modellierung von exemplarischen und vollständigen Strukturen und Verhalten eingesetzt werden, eignen sie sich in unterschiedlicher Weise zur Generierung von Code. Abbildung 4.3 zeigt, welche Diagrammart hauptsächlich (dicker Pfeil) und nebenbei (dünner Pfeil) für welche Form der Code- beziehungsweise Testgenerierung eingesetzt wird. Es ist aber festzuhalten, dass sich nicht alle Konzepte der UML/P-Dokumente zur Codegenerierung eignen. UML/P erlaubt grundsätzlich die Abstraktion von Details, zum Beispiel durch Auslassen von Typinformation bei Attributen oder durch Unterspezifikation bei Methoden und Transitionen, so dass die Fähigkeit zur Code- und Testgenerierung aus einem UML/P-Artefakt unter anderem von dessen Vollständigkeit abhängt. Intelligente Generierungsalgorithmen können natürlich auch unvollständige Artefakte zur Generierung nutzen, indem sie die offenen Aspekte durch Defaults ausfüllen oder intelligent raten. So kann zum Beispiel bei einem unvollständigen Statechart ein standardmäßiges Fehlerverhalten hinzugefügt werden und bei Attributen ohne Typinformation versucht werden, durch Typinferenz an den Stellen der Attributnutzung den benötigten Typ auszurechnen.
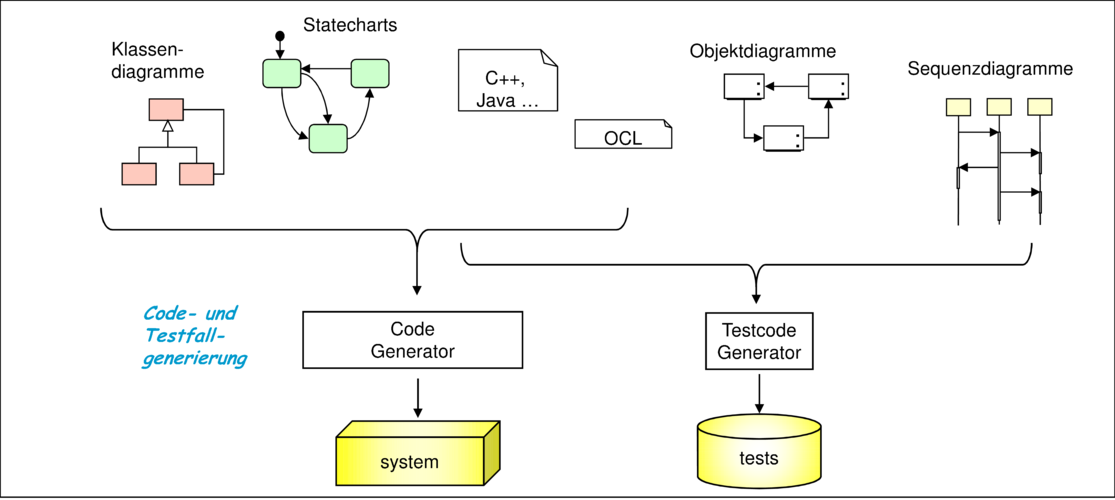
Der generierte Produktionscode kann dabei je nach Verwendungszweck mit zusätzlichem Testcode instrumentiert sein. So können für Testzwecke Inspektionsmethoden, interaktive Haltepunkte, Funktionen zum Zugriff auf private Attribute oder die Prüfung von Invarianten in den Produktionscode integriert sein, die bei der Erzeugung des Produktionscode für den Einsatz als fertiges Produkt weggelassen werden. Diese Form der Instrumentierung birgt Probleme, wenn der optionale Code Seiteneffekte beinhaltet, die das Verhalten des instrumentierten Produktionscodes verändern. Es ist deshalb wichtig, dass eine solche Instrumentierung nicht manuell, sondern von Codegeneratoren durchgeführt wird, so dass verhaltensverändernde Seiteneffekte ausgeschlossen werden können. Die durch die Instrumentierung entstandene Veränderung des zeitlichen Verhaltens muss in nebenläufigen Systemen unter gesonderten Gesichtspunkten betrachtet werden.
4.1.3 Tests und Implementierung aus dem gleichen Modell
Wie im vorherigen Abschnitt diskutiert, lassen sich aus manchen Modellen einerseits Tests, andererseits aber auch konstruktiver Code generieren. Die Generierung beider Codearten aus demselben Modell kann jedoch kein zusätzliches Vertrauen in die Richtigkeit des erstellten Systems erzeugen. Werden aus einem falschen Modell sowohl fehlerhafter Implementierungscode erzeugt als auch die Tests für diese Implementierung abgeleitet, so sind die Tests in gleicher Weise falsch. Dies zeigt das folgende einfache Beispiel, das den Absolutwert einer Zahl berechnen soll:
OCL  context int abs(int val) context int abs(int val) |
| pre: true |
| post: result==-val |
Die Codegenerierung kann damit folgenden Java-Code erstellen:
Java  int abs(int val) { int abs(int val) { |
| return -val; |
| } |
Eine typische Sammlung von Tests benötigt mehrere Eingabewerte, auf denen getestet wird. Als gute Standardwerte haben sich für den Datentyp int Sammlungen von Zahlen der Form -n,-2,-1,0,1,2,n für einige große n herausgestellt.10 Normalerweise werden diese vom Entwickler vorgegeben. Die erwarteten Ergebnisse müssen nicht separiert ausgerechnet werden, da mit der Nachbedingung eine Möglichkeit zur Prüfung der Korrektheit des Ergebnisses existiert. Folgender Testcode würde erzeugt werden können:
Java/P  int val[] = new int[] {-1234567,-2,-1,0,1,2,3675675}; int val[] = new int[] {-1234567,-2,-1,0,1,2,3675675}; |
| for(int i = 0; i<val.length; i++) { |
| int result = abs(val); |
| ocl result==-val; |
| } |
Da der Testcode genauso falsch ist wie die Implementierung, würde der Fehler damit nicht erkannt werden. In so einer Situation wird eigentlich nicht der implementierte Code getestet, sondern es wird getestet, ob der Codegenerator korrekt funktioniert. Denn wenn in dieser Situation ein Fehler gemeldet werden würde, dann würde der nur auf eine Inkonsistenz zwischen dem generierten Code und dem ebenfalls generierten Testtreiber hinweisen. Ein solches Vorgehen ist genau dann interessant, wenn die Parametrisierung des Generators getestet werden soll.
Als Konsequenz dieser Beobachtung ergibt sich, dass das konstruktive, zur Codegenerierung verwendete Modell und das Testmodell getrennt modelliert werden müssen. Dabei dürfen Fragmente des Test- und des konstruktiven Modells in denselben Diagrammen dargestellt sein. Es ist jedoch klar zu trennen, welche Konzepte wofür verwendet werden. Beispielsweise werden Statecharts im Wesentlichen konstruktiv eingesetzt. Die in den Statecharts verwendbaren Zustandsinvarianten werden jedoch bis auf Ausnahmen nur zur Prüfung in Tests eingesetzt.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |