Übersicht
Inhaltsverzeichnis
Vorwort
1 Einführung
2 Klassendiagramme
3 Object Constraint Language
4 Objektdiagramme
5 Statecharts
6 Sequenzdiagramme
A Sprachdarstellung durch Syntaxklassendiagramme
B Java
C Die Syntax der UML/P
C.1 UML/P-Syntax Übersicht
C.2 Klassendiagramme
C.3 OCL
C.4 Objektdiagramme
C.5 Statecharts
C.6 Sequenzdiagramme
D Anwendungsbeispiel: Internet-basiertes Auktionssystem
Literatur
| << zurück | MBSE Home | weiter >> |
C.2 Klassendiagramme
In diesem Abschnitt werden zunächst die Kernteile eines Klassendiagramms definiert, dann die Ergänzung der textuellen Teile vorgenommen und schließlich Stereotypen und Merkmale durch eine Grammatik dargestellt.
C.2.1 Kernteile eines Klassendiagramms
Eine wesentliche Diagrammform der UML/P ist das ⟨Klassendiagramm⟩, das in Abbildung C.2 definiert wird. In ihm werden neben diesem Nichtterminal eine Anzahl weiterer Sprachelemente eingeführt und definiert. Dazu gehören Syntaxklassen wie ⟨Klassifikator⟩ genauso wie die Beziehungen der syntaktischen Elemente untereinander, die durch Syntaxassoziationen wie implements dargestellt werden.
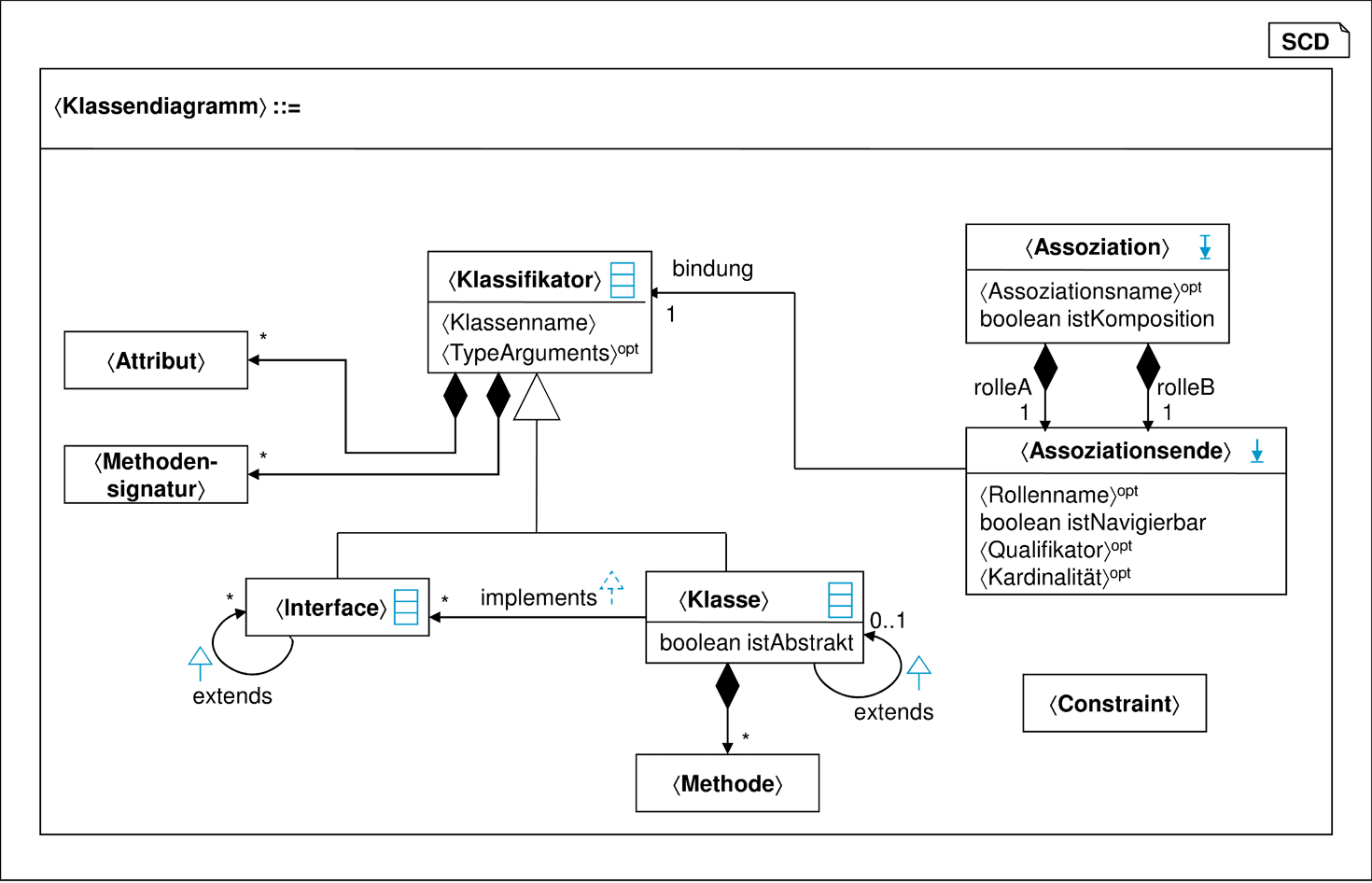
Das in Abbildung C.2 gegebene Syntaxklassendiagramm ist rechts oben mit SCD markiert, um anzuzeigen, dass es sich nicht um ein normales Klassendiagramm handelt. Eine detaillierte Beschreibung von SCDs ist im Anhang A zu finden.
Aus dem Softwareengineering ist bekannt, dass es fast immer mehrere Varianten für die Modellierung eines Sachverhalts gibt. Das gilt auch für die Darstellung der internen Struktur einer Sprache. Die in Abbildung C.2 modellierte Struktur von Klassendiagrammen wurde gewählt, weil sie eine gewisse Übereinstimmung mit dem im UML-Standard [OMG10a] gegebenen Metamodell hat. Abweichungen sind vor allem durch einige Vereinfachungen möglich geworden, die teilweise darauf beruhen, dass textuelle Anteile der Sprache im Folgenden durch eine EBNF-Grammatik dargestellt werden.
Kommentare, wie beispielsweise der in Abbildung 2.3 gezeigte, werden wie bei Sprachdefinitionen üblich nicht explizit aufgenommen. Dennoch sind sowohl graphische Elemente mit Kommentaren annotierbar, als auch textuelle Kommentare möglich und sinnvoll. Textuelle Kommentare werden wie bei Java üblich mit // eingeleitet, oder in /⋆…⋆/ eingeschlossen.
C.2.2 Textteile eines Klassendiagramms
In Abbildung C.2 wurden die Nichtterminale ⟨Methodensignatur⟩, ⟨Methode⟩ und ⟨Attribut⟩ nicht weiter detailliert. Darüber hinaus wurden mehrere Nichtterminale als Typen von Syntaxattributen verwendet, die ebenfalls zu definieren sind. Zum Beispiel ist ⟨Klassenname⟩ ein Syntaxattribut, das der Syntaxklasse ⟨Klassifikator⟩ zugeordnet ist. Für die Darstellung dieser textuellen Anteile werden die in Abbildung C.3 gegebenen Produktionen verwendet.1
| ⟨Klassenname⟩ | ::= | ⟨TypeB.2 ⟩ |
| ⟨Assoziationsname⟩ | ::= | /opt ⟨IdentifierB.1⟩ |
| ⟨Rollenname⟩ | ::= | ⟨Modifikatoren⟩ ⟨IdentifierB.1⟩ |
| ⟨Qualifikator⟩ | ::= | ⟨IdentifierB.1⟩ | ⟨TypeB.2⟩ |
| ⟨Kardinalität⟩ | ::= | 1 | 0..1 | ⋆ |
| ⟨Sichtbarkeit⟩ | ::= | + | # | - | ? |
| ⟨Attribut⟩ | ::= | ⟨Modifikatoren⟩ ⟨VarDeklaration⟩ |
| ⟨Modifikatoren⟩ | ::= | /opt { ⟨Sichtbarkeit⟩ | ⟨ModifierB.3⟩ }* |
| ⟨VarDeklaration⟩ | ::= | ⟨TypKardinalität⟩opt ⟨IdentifierB.1⟩ []* |
| { = ⟨ExpressionB.6⟩ }opt |
| ⟨TypKardinalität⟩ | ::= | ⟨TypeB.2⟩ { [ ⟨Kardinalität⟩ ] }opt |
| ⟨Methode⟩ | ::= | ⟨Methodensignatur⟩ ⟨BlockB.5⟩opt |
| | | ⟨Konstruktorsignatur⟩ ⟨BlockB.5⟩opt |
| ⟨Methodensignatur⟩ | ::= | ⟨Modifikatoren⟩ ⟨TypeVoidB.2⟩opt ⟨IdentifierB.1⟩ |
| ⟨FormalParametersB.4⟩opt []* ⟨ThrowsB.4⟩ |
| ⟨Konstruktorsignatur⟩ |
| ::= | ⟨Modifikatoren⟩ ⟨IdentifierB.1⟩ |
| ⟨FormalParametersB.4⟩opt ⟨ThrowsB.4⟩ |
In Java ist es üblich, dass Klassennamen mit Großbuchstaben beginnen. Das kann durch geeignete und automatisch überprüfbare Kontextbedingungen sichergestellt werden.
Die Nichtterminale in der UML/P-Grammatik wurden soweit möglich und sinnvoll aus den UML- und Java-Sprachdefinitionen übernommen und ins Deutsche übertragen. Die mittlerweile weitverbreitete und aus Java-Codierungsstandards bekannte Technik bei zusammengesetzten Wörtern, den Anfangsbuchstaben des zweiten Wortes groß zu schreiben, wurde nur dann eingesetzt, wenn das erste Wort verkürzt wurde. Zum Beispiel steht „VarDeklaration“ für „Variablendeklaration“, wobei sich durch Einsatz der Kapitalisierungs-Technik die Lesbarkeit erhöht. Um jedoch einen nahtlosen Übergang zwischen UML/P und Java zu ermöglichen, orientieren sich diese Produktionen weitgehend an dem Java-Sprachstandard [GJSB05] beziehungsweise der im Anhang B gegebenen EBNF-Darstellung des Java-Sprachstandards, die englische Nichtterminalnamen benutzt.
Bei einem Vergleich der Produktionen in Abbildung C.3 mit der im Java-Sprachstandard [GJSB05] gegebenen Grammatik beziehungsweise ihrer EBNF-Darstellung im Anhang B fällt auf, dass in Klassendiagrammen einige Angaben optional sind. Während in einer Programmiersprache grundsätzlich alle Definitionen vollständig sein müssen, können in einer Modellierungssprache wie UML/P beispielsweise Typdefinitionen für Attribute oder Parameter sowie die gesamte Parameterliste für Methoden fehlen. Für die Generierung von Java-Code sind diese Informationen dann aus anderen Quellen, zum Beispiel anderen Klassendiagrammen, zu extrahieren. Die Möglichkeit, diese Information zunächst offen zu lassen, erlaubt dem Modellierer eine für Kommunikationszwecke geeignete abstrakte Darstellung eines Sachverhalts und das Abstrahieren von Detailinformationen, wenn diese zum Zeitpunkt der Modellerstellung noch nicht ausreichend bekannt oder konsolidiert ist.
Die in Abbildung C.2 und der Abbildung C.3 gegebene Grammatik erlaubt die Festlegung der Sichtbarkeit von Attributen und Methoden grundsätzlich auf zwei Arten. Die eher ikonischen Sichtbarkeitsangaben „+“, „#“, „?“ und „-“ können alternativ durch Java-Modifikatoren wie beispielsweise public ausgedrückt werden. Weitere aus Java bekannte Modifikatoren wie zum Beispiel final haben in der UML keine graphische Entsprechung. Sie werden deshalb in der UML/P direkt eingesetzt. Jedoch wird empfohlen, derartige Informationen nur sehr sparsam in Klassendiagrammen darzustellen, weil Klassendiagramme dadurch sehr leicht überladen wirken. In einer Modellierungssprache gilt im Gegensatz zu einer Programmiersprache grundsätzlich, dass die Abwesenheit einer Information nicht automatisch auf eine Realisierung durch einen Default schließen lässt. Modelle erlauben grundsätzlich Abstraktion. Bei Klassendiagrammen manifestiert sich Abstraktion im Allgemeinen durch das Weglassen von Detailinformationen, beginnend bei Attributtypen, Modifikatoren, Attributen und Methoden bis hin zu ganzen Gruppen von Klassen. Das bedeutet, es ist dem Modellierer freigestellt, wie viel Detailinformation in Diagrammen dargestellt wird.
Auf eine detaillierte Erläuterung der Kontextbedingungen von Klassendiagrammen wird aufgrund deren Verbreitung hier verzichtet. Beispiele für Kontextbedingungen sind: Es dürfen in einer Klasse keine zwei Attribute mit denselben Namen definiert werden, alle verwendeten Datentypen müssen im UML-Modell existieren und Argumentanzahl und -typ bei Methodendeklaration und -aufrufen müssen kompatibel sein. Weitere Kontextbedingungen entstehen aus der Nutzung von Java als Zielsprache und aus dem UML-Standard für Klassendiagramme.
C.2.3 Merkmale und Stereotypen
Stereotypen und Merkmale dienen dazu, Modellelemente zu klassifizieren und ihnen zusätzliche Eigenschaften zuzuweisen. Abbildung C.4 führt die beiden Nichtterminale ⟨Stereotyp⟩ und ⟨Merkmal⟩ ein und zeigt wie Stereotypen und Merkmale angewandt werden. In Abschnitt 2.5.3 wird darüber hinaus eine Schablone zur Definition von Stereotypen eingeführt. Genau wie im UML-Standard wird hierfür eine eher informelle tabellarische Form zur Definition eines Stereotyps angeboten und die Schablone deshalb an dieser Stelle nicht durch eine abstrakte Syntax umgesetzt.
| ⟨Merkmal⟩ | ::= | { ⟨Merkmalseintrag⟩,* } |
| ⟨Merkmalseintrag⟩ | ::= | ⟨Schlüsselwort⟩ { = ⟨Wert⟩ }opt |
| ⟨Schlüsselwort⟩ | ::= | ⟨IdentifierB.1⟩ |
| ⟨Wert⟩ | ::= | ⟨ExpressionB.6⟩ |
| ⟨Stereotyp⟩ | ::= | ≪ ⟨IdentifierB.1⟩ ≫ |
In den vorangegangenen Definitionen der Syntax für Klassendiagramme in der Abbildung C.2 und der Abbildung C.3 wurden weder Merkmale noch Stereotypen explizit eingeführt. Weil Merkmale und Stereotypen eher generisch sind, um zusätzliche Eigenschaften für Modellelemente zu definieren, und auf alle Modellelemente gleichermaßen angewandt werden können, wird auch in den weiteren Grammatikdefinitionen der UML darauf verzichtet, beide explizit einzuführen. Eine explizite Erwähnung beider Elemente hätte eine Überladung der Syntaxdiagramme sowie der textuellen Grammatik zur Folge. Als Beispiel sei jedoch in Abbildung C.5 ein um Merkmale und Stereotypen vervollständigtes Syntaxdiagramm angegeben.
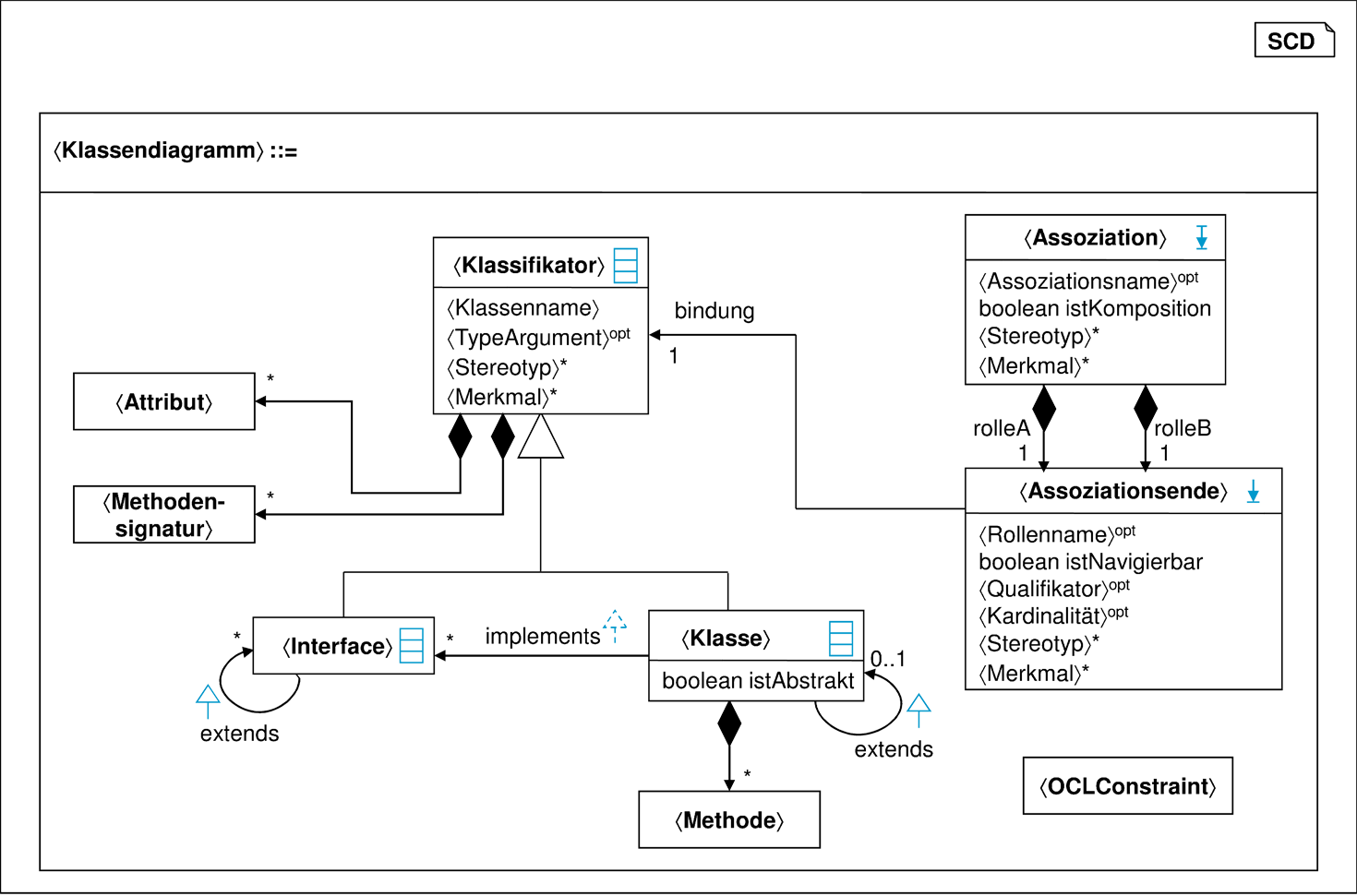
Der UML-Standard bietet ab der Version 1.4 die Möglichkeit, Modellelemente mit beliebig vielen Stereotypen zu dekorieren. Dies erlaubt zwar zusätzlichen Komfort bei der kompakten Modellierung von Sachverhalten, sollte jedoch mit Vorsicht eingesetzt werden, denn sonst entsteht eine ähnliche Unübersichtlichkeit des Modells, wie das vom Einsatz der Mehrfachvererbung bekannt ist. Auch textuell dargestellte Modellelemente sind mit Stereotypen und Merkmalen dekorierbar. Im UML-Standard werden dabei generell Stereotypen vorne und Merkmale hinten angefügt. Exemplarisch werden deshalb die Nichtterminale ⟨Attribut⟩ und ⟨Methodensignatur⟩ aus Abbildung C.3 wie folgt erweitert:
| ⟨Attribut⟩ | ::= | ⟨Stereotyp⟩* |
| ⟨Modifikatoren⟩ ⟨VarDeklaration⟩ |
| ⟨Merkmal⟩* |
| ⟨Methodensignatur⟩ | ::= | ⟨Stereotyp⟩* |
| ⟨Modifikatoren⟩ ⟨TypeVoidB.2⟩opt |
| ⟨IdentifierB.1⟩ ⟨FormalParametersB.4⟩opt []* ⟨ThrowsB.4⟩ |
| ⟨Merkmal⟩* |
Die beiden in Abschnitt 2.4 eingeführten Repräsentationsindikatoren „©“ und „… “ charakterisieren die Voll- beziehungsweise Unvollständigkeit der Darstellung eines Modells. Beide Indikatoren wirken daher nicht auf das Modell selbst und können ähnlich wie Kommentare in der abstrakten Syntax von UML/P vernachlässigt werden.
C.2.4 Vergleich mit dem UML-Standard
Die in diesem Buch präsentierten Klassendiagramme variieren in einigen Punkten mit dem UML-Standard [OMG10a]. Die in der UML/P genutzten Klassendiagramme konzentrieren sich auf die für eine agile Entwicklungsmethode wesentlichen Aspekte. Einige für diese Zwecke weniger gebräuchlichen Konzepte werden deshalb hier nicht betrachtet. Interessant, aber nur in speziellem Kontext nutzbar, sind zum Beispiel die neuen Konstrukte wie die Teilmengenbeziehung für Assoziationen. Jedoch bietet UML/P auch einige Erweiterungen, die speziell für die in diesem Buch relevanten Aufgabenstellungen entwickelt wurden.
Der UML-Standard [OMG10a] und UML/P unterscheiden sich jedoch nicht nur in der Sprache, sondern auch in der Repräsentationsform, also der Sprachdefinition. Der UML-Standard präsentiert zunächst alle Modellelemente, wie Klassen, Objekte oder Zustände als eigenständige Einheiten. Er beschreibt deren Eigenschaften, Restriktionen sowie Einsatzgebiete und Zusammenhänge ohne auf die Einbettung des Modellelements in die graphische Repräsentation (Diagramm) intensiveren Bezug zu nehmen. Die Gruppierung der Modellelemente in Diagramme wie beispielsweise dem Klassendiagramm oder dem Statechart erfolgt erst im Anschluss. Dem gegenüber verfolgt dieses Buch genau wie viele UML-Einführungen eine Diagramm-basierte Erklärung. So wurden in diesem Kapitel alle für Klassendiagramme interessanten Modellelemente erklärt. Eine Ausnahme bilden einzig Konsistenzbedingungen, die im nächsten Kapitel 3 gesondert behandelt werden.
Ein Vergleich zwischen UML/P und dem UML-Standard zeigt, dass in der UML/P folgende Modellelemente weggelassen, beziehungsweise nicht in voller Allgemeinheit einbezogen werden:
- Eine Reihe von Stereotypen wie beispielsweise ≪constructor≫ zur Markierung von Konstruktor-Methoden wurden nicht explizit eingeführt.
- Eine Klasse wird normalerweise mit drei Feldern (engl.: compartments) für den Namen, die Attribute und die Methodensignaturen dargestellt. In Analysemodellen sind weitere benannte Teile beispielsweise für Verantwortlichkeiten (engl.: responsibilities) möglich.
- Verschachtelte Klassen, wie sie beispielsweise Java anbietet, können in der UML ebenfalls dargestellt werden.
- Die UML bietet eine weitere kompakte Form zur Darstellung eines Interfaces im Klassendiagramm. Ein Interface wird dort in Form eines kleinen Kreises an Klassen angehängt, wenn diese das Interface implementieren.
- Abhängigkeiten (engl.: dependencies), wie beispielsweise die ≪use≫-Relation zur Darstellung syntaktischer Abhängigkeitsbeziehungen, werden in UML/P nicht verwendet.
- Die UML bietet parametrisierte Klassen und eine graphische Darstellung der Parameterbindung solcher Klassen.
- UML/P verzichtet auf die explizite Darstellung und Zugreifbarkeit der Metamodellierungs-Ebene innerhalb der Sprache selbst. Eine ausführlichere Diskussion von Motivation und Auswirkungen sind im Anhang A zu finden.
- Aufgrund der Vielfalt der Interpretationsmöglichkeiten für Aggregation (siehe [HSB99]) wurde auf die Einführung der schwachen Form der Aggregation (weiße Raute) verzichtet und nur die starke Komposition in Form einer schwarzen Raute erklärt.
- Assoziationen haben eine Reihe von Einschränkungen erfahren. So wurden die Kardinalitäten auf „1“, „0..1“ und „⋆“ beschränkt. Assoziationsklassen und mehrstellige Assoziationen wurden nicht eingeführt. Der Qualifikator bei qualifizierten Assoziationen wurde auf ein Element beschränkt, dafür aber ein Mechanismus angeboten, den Qualifikator mit einem Attribut der Zielklasse zu verbinden. Die Nicht-Navigierbarkeit einer Assoziationsrichtung wurde weggelassen, denn die Notwendigkeit zur Navigierbarkeit kann bei der Codegenerierung von einem Werkzeug selbständig erkannt werden.
- Einige Merkmale für die Vererbungsbeziehung wie beispielsweise {overlapping} wurden nicht eingeführt.
- Die UML/P bietet leicht andere Modifikatoren, wie etwa readonly für Attribute.
Viele der erwähnten Ergänzungen können ohne weiteres in UML/P integriert werden. Speziell die standardmäßig zur Verfügung gestellten sowie projekt- und unternehmensspezifische Stereotypen und Merkmale können, soweit sie für Dokumentationszwecke gedacht sind, einfach übernommen werden.
Gegenüber dem UML-Standard bietet UML/P jedoch die beiden Repräsentationsindikatoren „©“ und „… “, die dem Leser eines Diagramms zusätzlich Information über die Vollständigkeit des vorliegenden Diagramms vermitteln.
Außerdem wurde die von Programmiersprachen unabhängige Darstellung von Attributen und Methodensignaturen durch eine Java-konforme Fassung ersetzt. In UML/P werden statt „attribut: Typ“ deshalb „Typ attribut“ und statt „Pfad::Klasse“ für mit Pfaden qualifizierte Klassennamen entsprechend „Pfad.Klasse“ verwendet. Diese stärkere Java-Konformität besitzt bei der Umsetzung von Klassendiagrammen in Java-Code einige Vorteile. Insbesondere ist der Wiedererkennungseffekt für den Leser deutlich erhöht.
Eine wesentliche Eigenschaft der UML ist die Modifizierbarkeit ihrer Modellelemente mithilfe verschiedener Modifikatoren, Merkmale, Attribute, etc. Auch die Programmiersprache Java und EBNF kennen derartige Mechanismen. Weil diese Begriffe in unterschiedlichen Kontexten uneinheitlich verwendet werden und auch keine einheitliche Übersetzung der englischen Originale ins Deutsche existiert, wird in Abbildung C.6 eine Begriffsdefinition dieser Mechanismen vorgenommen, die für dieses Buch verwendet wird. Die wesentlichen Quellen für Definition und Übersetzung sind jeweils angegeben.
- Attribut
-
(engl.: attribute) ist ein Modellelement mit im Wesentlichen übereinstimmender Bedeutung in UML Klassendiagrammen und Java. Siehe Abbildung 2.2.
In attributierten Grammatiken ist ein Attribut analog ein Speicherplatz bei einem Element der abstrakten Syntax. Attribute werden Nichtterminalen zugeordnet.
- Modifikator
-
(engl.: modifiers) wie public oder final kann in der UML und Java auf Klassen, Methoden und Attribute angewandt werden. Modifikatoren sind fester Bestandteil der Sprache: eigene Modifikatoren können nicht definiert werden.
Der englische Begriff adornment wird wegen seiner Sinnverwandtheit ebenfalls mit Modifikator übersetzt. Der UML-Sprachstandard [OMG10a] bezeichnet damit zum Beispiel Kardinalitäten und möglichen Navigationsrichtungen von Assoziationen.
- Sichtbarkeitsangabe
- (engl.: visibility) ist ein Modifikator, der speziell zur Beschreibung der Sichtbarkeit von Klassen, Methoden und Attributen dient. Siehe Abbildung 2.2.
- Merkmal
- (engl.: tagged value) kann auf ein beliebiges Modellelement angewandt werden. Ein Merkmal besteht aus Schlüsselwort und Wert. Merkmale sind frei definierbar. Siehe Abbildung 2.16.
- Stereotyp
- (engl.: stereotype) kann auf ein beliebiges Modellelement angewandt werden. Stereotypen sind frei definierbar. Siehe Abbildung 2.16.
- Indikator
- kennzeichnet die Repräsentation eines Modellelements in Bezug auf Vollständigkeit. Indikatoren sind „… “ und „©“.
Bernhard Rumpe. Agile Modellierung mit UML. Springer 2012
| << zurück | MBSE Home | weiter >> |